Anti-Scraping Techniques And How To Outsmart Them
Businesses collect scads of data for a variety of reasons: email address gathering, competitor analysis, social media management – you name it. Scraping the web using Python libraries like Scrapy, Requests, and Selenium or, occasionally, the Node.js Puppeteer library has become the norm.
But what do you do when you bump into the iron shield of anti-scraping tools while gathering data with Python or Node.js? If not too many ideas flash across your mind, this article is literally your stairway to heaven cause we’re about to learn the most common anti-scraping techniques and how to combat them.

Anti-scraping techniques
Detecting patterns & setting limits

Do you still remember that palm-fringed beach you hit last summer? Are you asking what it has to do with scraping? A lot! Visiting a website is like visiting a holiday destination. Just like you leave footsteps (hopefully, just them!) on that bounty beach, you leave traces like your IP address or location on every website you browse.
Detecting patterns means monitoring visitors’ behavior on a website and identifying unusual activity that doesn’t seem human. Yeah, it kinda sounds like spying… But let’s be honest – you can’t avoid that so let’s put all the drama away and understand one thing: if you send out tons of requests within a few seconds or from the same IP address, there’s a good chance you’re using automation.
Bot behavior might also be detected by static clicks on a page. Clicking on a button in the same spot many times or filling in text in different spaces simultaneously will signal a non-human behavior. What might happen when static clicks are detected is that a website returns a totally uninformative 403 response. Something like “403 error” and don’t expect any hints like “Too many requests.”

In a nutshell, as websites do identify non-human patterns, they tend to limit the rate of IP requests in a certain amount of time. Say, 20 requests in 10 minutes. If it goes beyond that, you’ll get automatically blocked. Some companies also limit the content that is available only in certain locations. It doesn’t really stop scrapers but defo gives them a harder time.
Altering HTML
Some scrapers like BeautifulSoup parse data using HTML tags and pre-defined properties such as selectors. For example, the well-known selectors XPath and CSS are used to define nodes and styled elements. So what some websites do on a regular basis is change those pre-defined properties and HTML tags.
Set your eyes on this code:
<div><p class="paragraph">Some text in Paragraph</p></div>
The XPath in a scraper would look like this:
//p[@class=’paragraph’]/text()
Websites might change the class name frequently so that a scraper would face difficulties every time the class name changes. For example, a website manager could easily rewrite the aforementioned code like this:
<div><p class="text">Some text in Paragraph</p></div>
Avoiding walls of text

Converting text into another format has emerged as one of the most popular ways to fight scrapers in the modern world. From plain text to PDFs, images, videos, etc. This sort of converting is quite fun, creative, and not that hard, but it’s not beer and skittles all the time. Although conversion does make scrapers’ lives more difficult, the user experience of such websites also slightly decreases because it takes more time for them to load.
Replacing static content with dynamic
Since most scrapers parse data through simple HTML, they often can’t render JavaScript-based websites. If you shift static data to dynamic, like emails and phone numbers, most scrapers won’t render such sites and will require a headless browser to read data encrypted with JavaScript.
Giving fake data
When a website detects a scraper, it might start feeding the scraper with fake information, which is known as cloaking. It might really put an end to reliable scraping as scrapers aren’t even notified that they’ve been spotted. So you might be gathering data that looks as good as real but, in fact, is totally spurious.
Using anti-scraping services
With fresh bots cropping up every day, it’s no wonder that there are many anti-scraping service providers trying to hunt those newbies and conquer the industry. Scrape Shield, Radware Bot Manager, and Imperva – just to name a few – are all on the same mission.
Most often, they provide not only scraper-blocking solutions but also some analytical tools. It might be a good idea to check those out so that you know what scrapers are dealing with. Knowing a full package of what’s hiding under the umbrella term of anti-scraping services proves particularly useful when picking up a scraper for your specific needs.
Having CAPTCHAs

Hmm, CAPTCHAs, CAPTCHAs… These are renowned for making not only bots but also many people pretty mad. Captcha stands for Completely Automated Public Turing test to tell Computers and Humans Apart. It’s used when a website suspects unusual activity and wants to check if it’s a scraper (bot) or a human being that’s trying to access the content of that page.
There are several types of captchas. Character-based captchas consist of letters and numbers and are pretty easy to crack, but image-based captchas are tougher. When websites become extremely impatient with bots, they add audio-based captchas, handling which is as difficult as nailing jelly to a tree.
Last but not least, creating captchas isn’t an uphill struggle these days. Some websites trust Recaptcha, i.e. a Google service that allows people to use already made captchas free of charge. Yeah, that almighty Google…
How to combat those anti-scraping tools
We’re sure that you’ve got a good picture of how anti-scraping works. But now let’s see how you can take up arms to fight anti-scraping tools and successfully access the content that is shielded by those bot haters.
Delay your requests
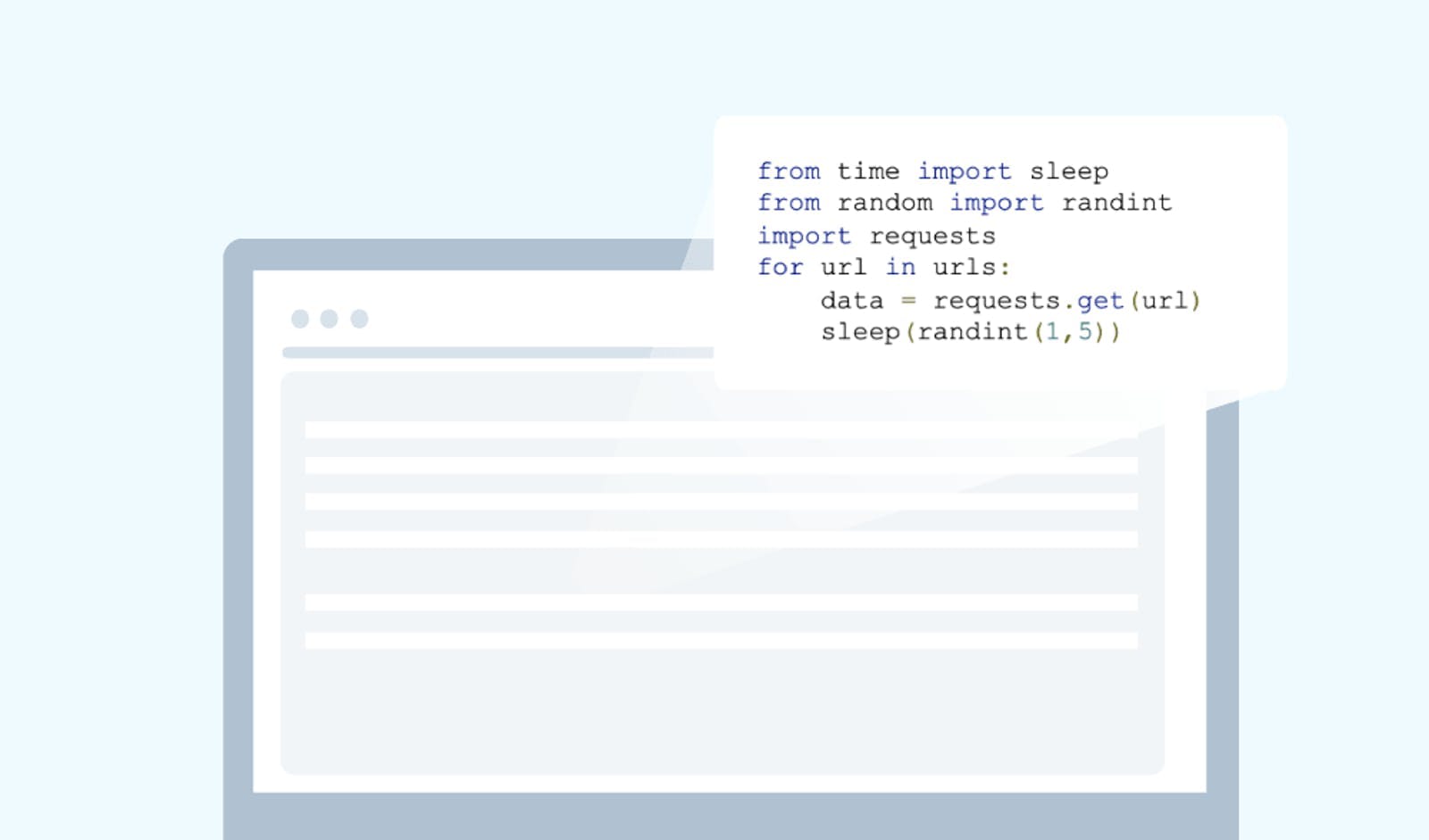
Scrapers often get banned because of sending too many requests too quickly. Anti-scraping techniques are designed to detect this unusual behavior and ban the IP. To prevent this, delay some of your requests.
The time module in Python is good for this, but a smart anti-scraping tool can still detect it. Thus, to display a human-like behavior, choose the random option under the time module.
from time import sleepfrom random import randintimport requestsfor url in urls:data = requests.get(url)sleep(randint(1,5))
For Scrapy, enable auto-throttle in setting.py:
AUTOTHROTTLE_ENABLED = trueDOWNLOAD_DELAY = 0.25
Use random user agents
The user agent is a request header that helps servers identify a person trying to access a website. The header contains different information about the person, including the app, browser, and OS that are used to read the content. This means that having the same user agent for many requests will lead to detection and maybe even a ban in the end.
Different user agents are very helpful for bypassing anti-scraping tools. All you need to do is access a list of various user agents so that you could get random IPs for each of your requests. One of the easiest ways to get a unique fingerprint is X-Browser, a Smartproxy’s anti-detection management tool. It gives you a unique fingerprint for each profile so that all of them would be traced back to different users, but not you.
To manage different user agents in Python, use the random.choice(list_of_ua) module, which will select user agents randomly:
ualist = [“Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10_6_0 rv:4.0; sl-SI) AppleWebKit/532.26.1 (KHTML, like Gecko) Version/5.1 Safari/532.26.1”,“Mozilla/5.0 (Windows; U; Windows CE) AppleWebKit/533.23.6 (KHTML, like Gecko) Version/4.1 Safari/533.23.6"]for url in urls:data = requests.get(url=url,header={ 'User-Agent': random.choice(ualist)})
As for Scrapy, install pip installscrapy-user-agents and enable the scrapy-user-agents module in settings.py:
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,'scrapy_user_agents.middlewares.RandomUserAgentMiddleware': 400,}
Get proxies
One thing should already be as clear as daylight – if you send frequent connection requests from a single IP address, you’re bound to get banned. That’s why proxies are of the utmost importance if you want to scrape the web smoothly. Sending each request with a different IP will make your scraper look like a human, which will decrease the risk of getting those IPs banned.
At Smartproxy, we have two types of IP sessions, namely rotating and sticky. Rotating IP sessions will automatically change IPs with every connection request. Sticky IP sessions will keep an IP address the same for an extended period of time (up to 30 minutes). For web scraping, go with rotating sessions.
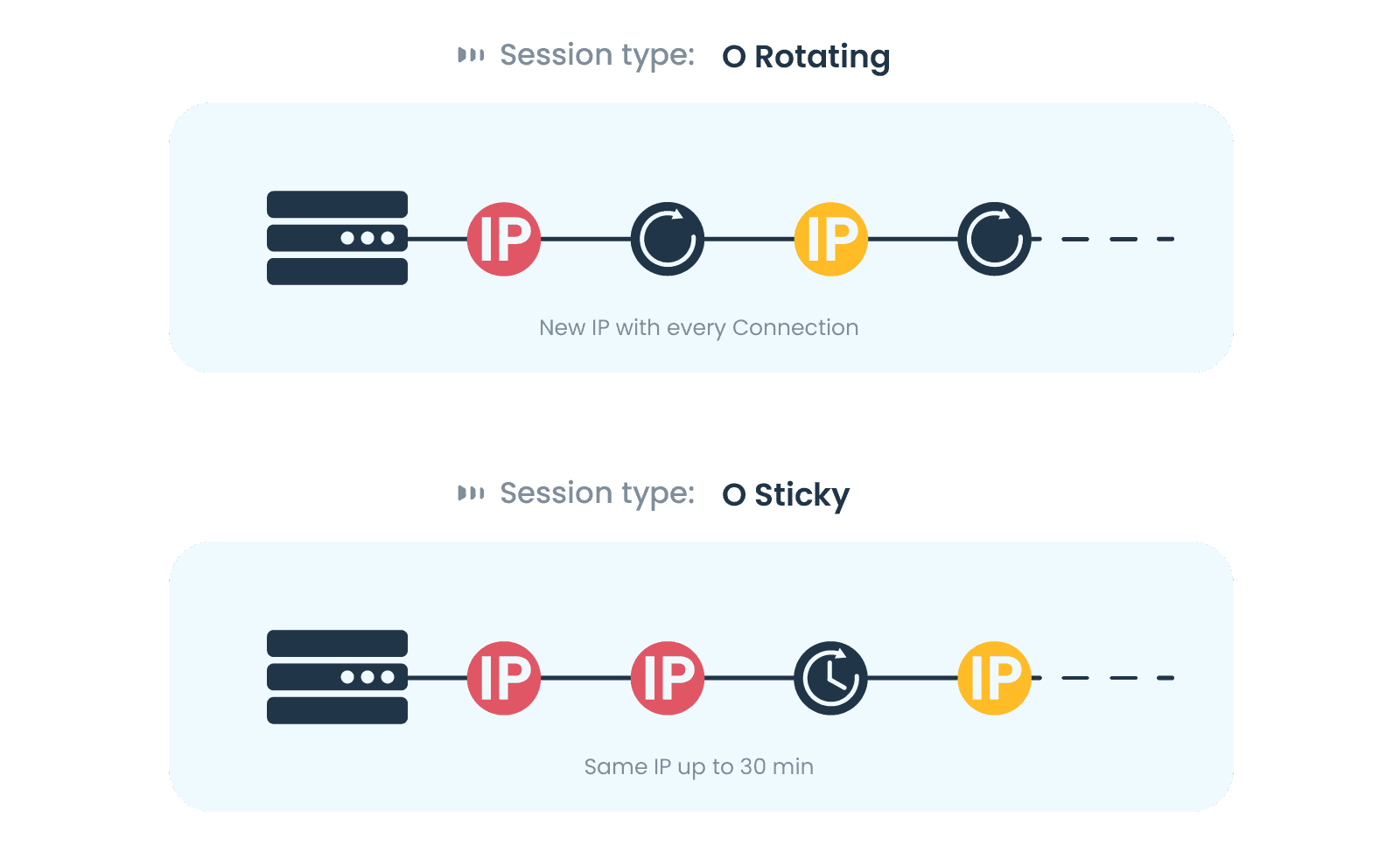
So once you buy proxies and access a pool of IPs, you’ll be able to send each request with a random IP address. In Python, you can do so by using the requests library with our rotating residential proxies:
import requestsurl = 'https://ipinfo.io'username = 'username'password = 'password'proxy = f'http://{username}:{password}@gate.smartproxy.com:7000'response = requests.get(url, proxies={'http': proxy, 'https': proxy})print(response.text)
The installation process with Scrapy is another story. On the Terminal window of your computer, navigate to the main directory of your project folder using cd yourprojectname and download our proxy middleware typing in this command:
curl https://raw.githubusercontent.com/Smartproxy/Scrapy-Middleware/master/smartproxy_auth.py > smartproxy_auth.py
Having done that, you’ll have to do another tini-mini task – the configuration of settings for our proxy authentication. But the good news is that doing so isn’t rocket science. Simply navigate to your project folder, access the settings.py file using an editor of your choice, and add the following properties at the bottom:
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,'yourprojectname.smartproxy_auth.ProxyMiddleware': 100,}SMARTPROXY_USER = 'username'SMARTPROXY_PASSWORD = 'password'SMARTPROXY_ENDPOINT = 'gate.smartproxy.com'SMARTPROXY_PORT = '7000'
Here, the user and the password refer to your Smartproxy username (or sub-user) and its passcode. For more information on development with Scrapy, access GitHub.
In a few words
Web scraping has become a serious challenge in the present day. Websites do whatever they can to identify and ban bots. Detecting patterns, setting limits, altering HTML, avoiding walls of text, replacing static content with dynamic, and using CAPTCHAs – and the list goes on.
Yet, don’t be as weak as a blown bicep! Using random user agents and delaying requests might help, but don’t forget that the real fuel for your web scraping machinery is proxies. Contact Smartproxy to get your proxies now!
About the author

James Keenan
Senior content writer
The automation and anonymity evangelist at Smartproxy. He believes in data freedom and everyone’s right to become a self-starter. James is here to share knowledge and help you succeed with residential proxies.
All information on Smartproxy Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may belinked therein.