



Digesting parsing: what is parsing? [VIDEO]
Data parsing is the process of converting raw, unstructured data into well-structured and understandable information. In this article, we’ll explore what data parsing is, how it works, and the various parsing technologies that unlock a range of features to both businesses and individuals.

What is data parsing?
In the main, data parsing is a process when computer software converts a string of often illegible data into a readable format that is easily understood. There are a few synonyms for this process, including syntax analysis and syntactic analysis.
On a more technical level, a data parser is a software component that uses input data (e.g. HTML) to build a structural, readable representation of that input.
Parsers work with different formats of data. Everything depends on the code and the set of rules on which it’s built. For example, a parser can extract the needed information from an HTML string and convert it into JSON, CSV, a chart, or a table.

How does parsing work?
Parsing is not a straightforward process of analyzing strings of symbols in a computer language. It’s a two-step procedure where a parser is programmatically developed to know which data to read and how to analyze and transform it.
There are two components making up a data parser – lexical analysis and syntactic analysis. These are followed by semantic analysis, which doesn’t really fit under the umbrella of parsing but always goes after it. Below, we’re gonna digest all of them.
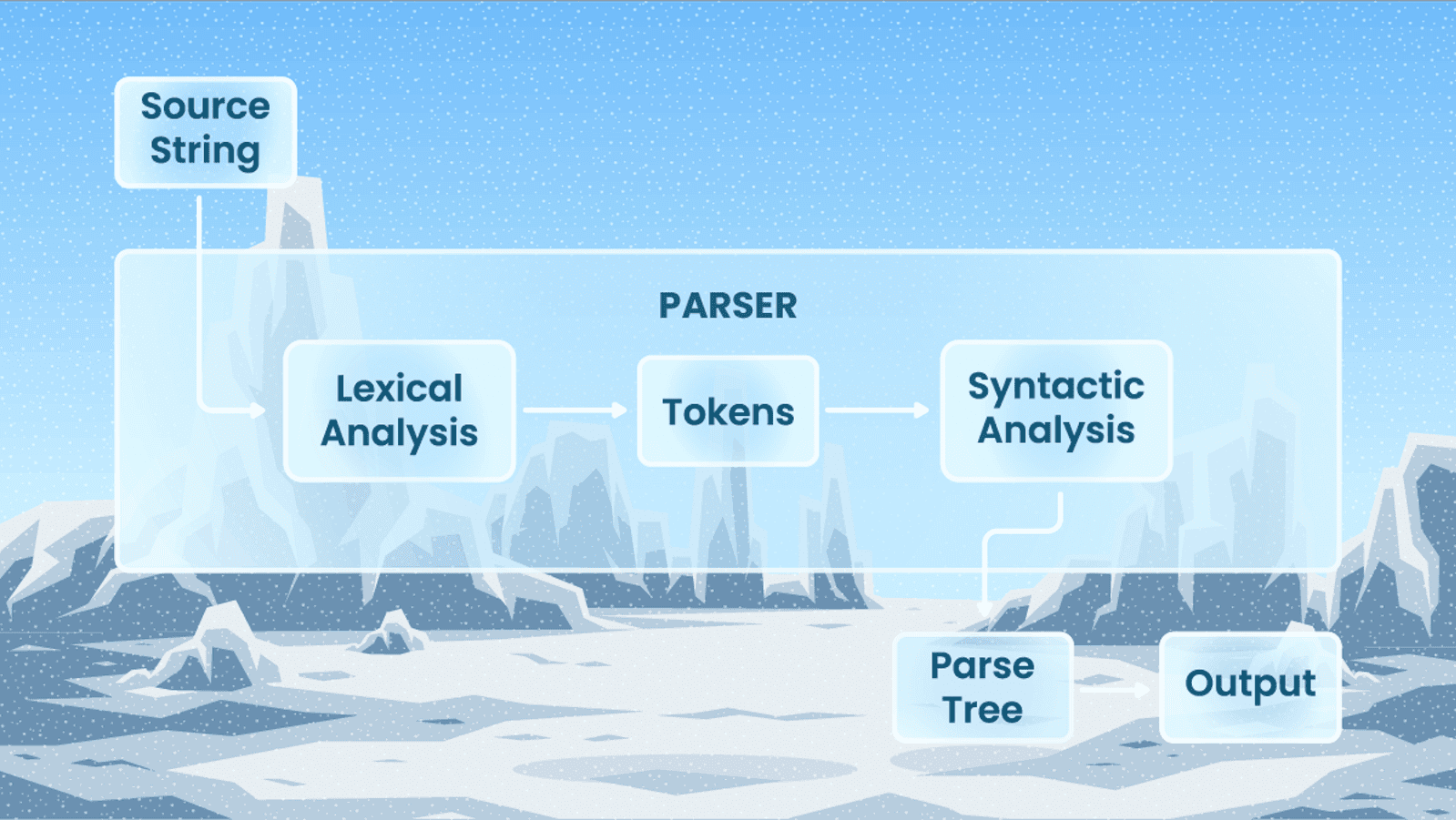
Lexical analysis
This is the first step of data parsing. It all starts when a string of raw, unstructured data enters the parser. Then, a lexer, also known as a scanner or tokenizer, transforms that stream of data into a sequence of tokens.
This step is lexical because the parser creates tokens by establishing meaningful lexical units, such as delimiters and keywords. At the same time, the parser discards lexically irrelevant information, such as parenthesis, comments, and white spaces.
Let’s say, the input character stream (2 + 8)^3 enters the parser. The lexer will split this stream into the following tokens: (, 2, +, 8,), ^, 3. Basically, lexical analysis is a process of token generation.
Syntactic analysis
The next stage is checking if the generated tokens make up an allowable, meaningful expression in accordance with pre-defined rules. Sounds super tricky? Keep on reading, we’ll try to make it clearer.
Here we need to introduce one more concept from computer sciences – context-free grammar. It’s a set of rules that specify the syntax of a language. Simply put, context-free grammar is about computer codes that define what is a valid sequence of tokens. It clearly defines what components can make up a valid expression in tokens and the order in which those components must go.
The result of syntactic analysis is a parse tree, consisting of branches with leaf nodes. Drawing a parse tree means drawing a hierarchical structure that shows which elements in the initial input are meaningful and what their role is.
In its simplest form, lexical analysis creates tokens, while syntactic analysis draws trees from those tokens.
Semantic analysis
The concept of parsing doesn’t include semantic analysis but this is something that always follows parsing. It’s performed by semantic analyzers, not parsers themselves.
Semantic analysis is a process of translating the initial source code (written in a high-level programming language) into object code (written in a low-level programming language). It’s a process that transforms source code into an executable program.
At this stage, semantic analyzers identify all the remaining errors from syntax analysis and generate an annotated parse tree, also known as an error-free parse tree. This stage is vital because parsing can’t detect all the errors in the source code.
If the initial string of symbols is free of errors, semantic analysis gives the green light for raw and unstructured data to become a clearly readable piece of information.
Types of parsers
The primary purpose of using parsers is to determine whether the input can be derived from the initial string of symbols, based on a pre-defined set of rules. There are two ways to do that: top-down and bottom-up.

Parsing technologies
Data parsers go along with various technologies as they’re extremely flexible. Take a look at some examples of technologies that go hand in hand with parsing:
1. Markup languages.
HTML stands for Hypertext Markup Language. Developers use it to create websites and website apps that display data. XML is short for eXtensible Markup Language. It sets rules for encoding documents in a format that is human-and machine-readable.
2. Internet protocols.
Internet protocol languages such as Hypertext Transfer Protocol Secure (HTTPS) are at the heart of data communication for the internet. These protocols ensure secure communication over a computer network.
3. Database languages.
These languages help us read, update, and store information on databases. For example, SQL, or Structured Query Language, is one of the most popular programming languages that allows managing data in database systems.
4. Scripting languages.
These are programming languages that automate the execution of tasks without human interaction. Such languages define a series of commands that need no compiling. Web apps, multimedia, games, extensions, and plugins – all of them use script languages.
5. Modeling languages.
It’s an artificial graphical or textual language that expresses information in a specific structure defined by a set of certain rules. Developers, analysts, and investors use modeling languages to understand how the systems that they’re interested in work.
6. Interactive data languages.
IDL, i.e. interactive data language, is a programming language that proves extremely useful in data analysis and data visualization. Specialists from space sciences and solar physics use IDL on a daily basis.
7. General-purpose programming languages.
It’s quite likely that Java is the most popular programming language of this kind. It’s a class-based, object-oriented language that boasts its portability. Once you have written code for a Java program on a computer, it’s very easy to move that code to mobile.
How we do parsing at Smartproxy
Here at Smartproxy, we’re obsessed with data. That’s why we have a bunch of tools that can make your data scraping fast, smooth, and beneficial. First of all, if you’re using fully-developed products like Octoparse or Scrapy, don’t forget to employ residential proxies to boost parsing with those tools.
But the best thing is that we have our own solutions which can parse data. Our No-Code Scraper offers a selector that can identify and choose multiple fields of the same value with a single click. It’ll provide you with a table preview of collected data and the possibility to instantly export data in JSON or CSV formats.
In case your goal is to send millions of queries on Google, the simple proxy extension won’t work. For such tasks, you’ll need special tool, SERP Scraping API. It's easy to use. Just specify your query or URL, and Smartproxy will return well-formatted data in JSON.
Why parsing and artificial intelligence (AI) are inseparable friends?
So now we know that the data we get from web scraping is not well-structured and so lacks meaning if it’s not parsed correctly. We also established that parsing data is extremely complex. And it’s not only because parsing consists of two analyses, followed by semantic analysis.
The nature of the website structure is highly dynamic, too. Just imagine all those billions of websites around the world. All of them are different: their programming uses various codes, their formats keep changing all the time… That’s why parsers need maintenance and should adapt to different page formats.
If you had to keep up with the dynamics of web structures on your own, that’d take a lot of manual work, time, and resources. And still, you’d be extremely unlikely to fulfil all the tasks.
The solution here is to employ artificial intelligence (AI) along the way. AI will automate maintenance tasks and conduct your business operations at the speed of light. That’s why data parsing in the modern world is just impossible without the help of some “intelligence.”

What is Natural Language Processing (NLP)?
Natural language processing, or NLP for short, is a subfield of artificial intelligence that aims to define how to program computers to process, analyze, and represent large amounts of human language data. That said, we can’t imagine parsing without natural language processing.
Since natural language processing is all about how computers analyze and process extensive natural language data, parsing is not the only field where NLP plays a significant role. NLP is an essential part of the following area (just to mention a few):
- Machine translation
- Optical character recognition (OCR)
- Chatbots
- Voice enablement
- Statistics
So NLP is the technology that makes interactions between computers and human language possible. It empowers computers to comprehend natural language input and provide natural language output properly.
Parsing in soft sciences
When somebody hears “parsing,” they tend to associate it with computer science. And they are totally right! Computer geeks often talk about parsing in programming, Python, PHP, XML, JSON, HTML, Javascript, Java, or C++. Even this blog post so far has looked at parsing from a more technical point of view.
Yet, did you know that parsing also exists outside programming? Are you asking how this is possible? Below, you’ll discover how you can parse data in soft sciences.
Parsing in linguistics, or what is sentence parsing?
To parse in linguistics means to divide a sentence into its constituents to understand the meaning of the sentence. The most popular tool to do that is sentence diagrams. They visually represent the syntactic construction of a sentence.
A traditional method to perform sentence parsing is to distinguish the sentence elements and their parts of speech, e.g. nouns, verbs, adjectives, etc. The reader also takes notice of other elements such as the grammatical tense of the sentence, i.e. present, past, or future. Having done all that, the reader uses this analysis to understand and interpret the meaning of the sentence.
To make things clear, consider this sentence:
- Max needs some proxies.
To parse this sentence, we first need to identify the biggest components of the sentence, namely noun and verb phrases. In this case, Max is a noun phrase and needs some proxies is a verb phrase.
It’s also interesting to notice that this isn’t a simple verb phrase. It includes not only a verb (needs) but also a noun phrase (some proxies).
Then, we need to go deeper and establish the part of speech of each word. In our example, we can see a proper noun (Max), verb (needs), determiner (some), and noun (proxies). Finally, since the verb is needs, we can understand that the action hasn’t happened and the sentence is in the present tense.
This is a simple example. Yet, it shows how parsing can help understand the meaning of a text. Such visualizations are particularly useful when analyzing extremely long and complex sentences.
Parsing in psychology
When we’re talking about parsing in psychology, we’re basically thinking of parsing in cognitive psychology (or psycholinguistics). It’s a field of study that analyzes the relationship between languages and psychology.
Scientists in this field study and explain how the brain processes language to transform signs and symbols into meaningful statements. They seek to understand how different brain structures facilitate language acquisition and comprehension.
A very simple example of parsing in psycholinguistics is word associations. For example, when we hear the word “sneakers,” we might think of the following attributes associated with this word: sports, running, training, Nike, Adidas, rubber, etc.
Summing everything up
Parsing is a wide topic that found its way outside computer science and paved the way for further applications in soft sciences. We hope that we’ve managed to bring your understanding of data parsing up to snuff.
If you’re after ways to boost your business, register now to begin using our tools. And oh, if you have any questions about data parsing, chat with our customer support!
About the author

James Keenan
Senior content writer
The automation and anonymity evangelist at Smartproxy. He believes in data freedom and everyone’s right to become a self-starter. James is here to share knowledge and help you succeed with residential proxies.
All information on Smartproxy Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may belinked therein.

