



A Complete Guide to Web Data Parsing Using Beautiful Soup in Python
Beautiful Soup is a widely used Python library that plays a vital role in data extraction. It offers powerful tools for parsing HTML and XML documents, making it possible to extract valuable data from web pages effortlessly. This library simplifies the often complex process of dealing with the unstructured content found on the internet, allowing you to transform raw web data into a structured and usable format.
HTML document parsing plays a pivotal role in the world of information. The HTML data can be used further for data integration, analysis, and automation, covering everything from business intelligence to research and beyond. The web is a massive place full of valuable information; therefore, in this guide, we’ll employ various tools and scripts to explore the vast seas and teach them to bring back all the data.
What is data parsing?
Data parsing is the process of analyzing data to extract meaningful information or convert it into a more structured format. When speaking about web content, this data usually comes in the form of HTML documents. They are made up of many elements that hold everything together, and while they’re the building blocks of a website, we only care about the information stored in between. Through data parsing, we analyze these files to find data, clean it, and then put it into an easy-to-read format, such as a CSV or JSON file, for further analysis and use.
Parsing data is an essential part of the collecting data process. The cleaned data can be used for analysis and statistics, providing valuable insights for your personal or business needs. Another benefit of data parsing is that it can combine data from various sources, allowing you to create new and diverse datasets. For example, when gathering data from eCommerce websites, it can find, connect, and calculate the average price of competitor products. Knowledge like this can help you make informed decisions on pricing products on your website and stay ahead in the market.
One more cool thing is that collecting and processing data can be fully automated with intuitive functions. It reduces the need for manual data entry and manipulation, saving time and reducing the risk of human error. This means you’ve got a little elf watching your competitors, analyzing them, and providing valuable insights 24 hours a day, 365 days a year, with no coffee breaks or extended vacations. Beating your competition while asleep is quite a flex, don’t you think?
What is Beautiful Soup?
If you’ve already been hooked on the idea of data parsing, you probably tried to open an HTML document, read it for information, and felt like you were trying to decipher ancient hieroglyphs. You might’ve also looked at it and seen it as a bowl of soup – a bunch of ingredients thrown together, sliced, boiled, and cooked. Together, they make up a tasty meal, but if you tried to pick out every piece of carrot (for whatever reason), you might’ve realized what a complex job that is.
Beautiful Soup is here to the rescue to make your soup, well, more beautiful. It’s a Python library commonly used to scrape and parse HTML and XML documents with tools to navigate and search the content inside them. Beautiful Soup makes it easier for developers to extract and work with data in a more structured and readable format.
Installation and setup
Beautiful Soup installation is quick and easy. First, you’ll need Python on your computer or virtual environment with the pip packet manager to install Python libraries. From version 3.4+, pip comes installed by default. You can run this command in the Terminal to check if you have it:
py -m pip --version
Then, to install Beautiful Soup, simply run this command:
pip install beautifulsoup4
That’s it! The Python package should take a few seconds to install and will be ready for use in your web scraping project.
Beautiful Soup basics
You’ll want to test if everything works correctly first. Write a simple code to extract data from the following HTML structure file:
<!DOCTYPE html><html><head><title>Smartproxy's Scraping Tutorial</title></head><body><h1 class="main-heading">What is a residential proxy?</h1><p class="description">A residential proxy is an intermediary server between you and the website you're trying to access. This server has an IP address provided by an Internet Service Provider (ISP), not a data center. Each residential IP is a real mobile or desktop device that pinpoints a certain physical location.</p><h2>Residential proxy features</h2><ul id="proxy-features"><li class=>Premium quality and stability</li><li>Full anonymity and security</li><li>Large IP pool and worldwide targeting</li><li>Unlimited connections and threads</li></ul></body></html>
Create a new text file and name it website.html. Open the file in a text editor, paste the above code, and save it.
Next, create a Python script file in the same directory. Name it whatever you want, like your favorite type of soup, for example, miso_soup.py. Here’s the code snippet:
# Import the BeautifulSoup library to use in the codefrom bs4 import BeautifulSoup# We tell the script to open and read the website.html file and store it in the content variable. In a real application, this would be an actual website, but we'll get to that laterwith open('website.html', 'r') as f:content = f.read()# Here, we create a Beautiful Soup object using the built-in Python HTML parsersoup = BeautifulSoup(content, "html.parser")# Let's say we want to find the <h1> heading from the website.html file. If you check it out, you'll see it has a class named "main-heading"# To extract it, use the soup.find() method to find an element by its classheading = soup.find(class_="main-heading")# Finally, print the result. You can also write print(heading.text) to get rid of the HTML tags for a cleaner resultprint(heading)
Run the code with this command in the Terminal:
python miso_soup.py
The code will read the HTML document, parse it, find the element with a main-heading class, and print <h1 class="main-heading">What is a residential proxy?</h1> in your Terminal.
If you’ve received the same result, that's fantastic! Your setup works fine, and you’re ready to move on to the next steps. However, if you run into any issues, make sure to check if:
- you’re using the latest version of Python that comes with pip, and Beautiful Soup is installed;
- the miso_soup.py and website.html files are in the same directory (folder);
- you’re running the Python Terminal command in the same directory as your files;
- there aren’t any typos, minor spelling mistakes or other errors inside the code or file names.
That’s all for the basics. Next, we‘ll parse data from an actual website, where you’ll see how we can use what you’ve already learned and expand upon it.
Parse data with Beautiful Soup
To understand what it’s like to scrape and parse a website, we’ll use the ScrapeMe shop as our target. Don’t worry; it’s not a real thing – it’s an example website built to test scripts, which functions exactly as a regular online shop would. The only difference is that it sells Pokémon. It’s a perfect place to start, as real websites might have anti-scraping measures, such as CAPTCHAs or rate limitations, to prevent multiple automated requests. They can, however, be circumvented with the help of proxies, which we’ll use in our real-world example later.
One more thing – Beautiful Soup needs a friend. On its own, the library can’t scrape data. Therefore, we’ll need to install one more additional Python package to make HTTP requests:
pip install requests
Simply put, this web scraper library helps you make HTTP requests to a website, fetches the HTML code, and returns it to you. If you want to learn more, you can read about this library here.
Once more, let’s test if our setup and libraries work. We’ll take the previously written code and modify it so that it scrapes data from an actual website instead of a file:
from bs4 import BeautifulSoup# Import the requests libraryimport requests# Define a URL to scrape from. Then, use the requests.get() method from the requests library to make an HTTP request to the website and get a resulturl = "https://scrapeme.live/shop/"response = requests.get(url)soup = BeautifulSoup(response.content, "html.parser")# Remove this line, as we aren't picking a specific element and want to get the whole website# heading = soup.find(class_="main-heading")# Once again, we print the resultprint(soup)
After you run the above code, you should have the entire HTML page printed in your Terminal. Let’s look at how you can modify this code to extract specific HTML elements from a page and get more relevant information.
Find elements by ID or class name
The most common task in web parsing is to find an element within the soup of HTML. Luckily, most elements have attributes that help to identify them from one another. These can be anything the developer decides them to be, but the most common are ID and class attributes.
Let’s try a simple task – list the names of all Pokémon on the main page. Inspect the website’s source using Chrome developer tools (right-click on a page →Inspect) or your web browser equivalent. A window will open that displays the HTML of the page. The first item on the list is Bulbasaur. You can try to find it mentioned in the code or use the element selector and then click the name on the site. This will jump to the HTML part where the element is located.

The HTML element you need has a class named woocommerce-loop-product__title. If you check the other products, you can see they all have the same HTML class name. Let’s write a simple loop that will go through these HTML elements and print them out:
from bs4 import BeautifulSoupimport requestsurl = "https://scrapeme.live/shop/"response = requests.get(url)soup = BeautifulSoup(response.content, "html.parser")# Instead of soup.find(), we use soup.find_all() to get all elements with the same class nametitles = soup.find_all(class_="woocommerce-loop-product__title")# Loop through all of the results and print the text contentfor title in titles:print(title.text)
You’ll get a list of 16 items in your Terminal. Congratulations, you’ve just parsed data from an actual website! You can play around with the script to see what other content you can extract by changing which class Beautiful Soup should try to find.
Search multiple web pages
You’ve managed to print the names of 16 Pokémon, but what if you wanna catch ‘em all? The issue that stands in our way is that the store is separated into several HTML pages, and our script isn’t smart enough to navigate them to get everything.
Let’s help it out and check how the links work. Whenever you visit a new page, the URL changes to …/shop/page/x/ where x is the page number. This is great for us, as we can modify our script to iterate through every page simply by changing the number in the URL. This is how it can be done:
from bs4 import BeautifulSoupimport requestsurl = "https://scrapeme.live/shop/"# We move some elements around, as most of them need to be under a loop to be repeated every time the link changes# As an example, let's create a loop for the first 10 pages, as scraping all of them will take a while# The idea here is simple - open a page, scrape and parse the information, print it, go to the next page, repeatfor k in range(10):# We append the /page/[number] to the URL string. The [number] will start at 1, and increase by 1 with each iterationlink = url + "page/"+str(k+1)# The rest of the script is the same as before, except it is being repeated every loopresponse = requests.get(link)soup = BeautifulSoup(response.content, "html.parser")titles = soup.find_all(class_="woocommerce-loop-product__title")for title in titles:print(title.text)
The script's premise is simple, using what we already know from the previous example with an added loop. It is, however, handy to have an idea of how it’s done, as many websites will most likely not have all the information you need on their first page. If only it were that easy!
Find all links
Another widespread usage of data parsing is finding all the links in a website, otherwise known as web crawling. This can be useful for various reasons, such as indexing, seeing what your competitors are linking to, their website structure, and many other use cases.
Remember attributes? Well, this time, instead of using them as an identifier for HTML elements, we’re going to be looking for them instead. The most common way of linking is through the href attribute. Therefore, our task is very straightforward – find all the hrefs inside the HTML web page and print their content:
from bs4 import BeautifulSoupimport requestsurl = "https://scrapeme.live/shop/"response = requests.get(url)soup = BeautifulSoup(response.content, "html.parser")# Links are defined in <a> tags, therefore tell the script to find all of themlinks = soup.find_all('a')for link in links:# Use the .get() method to get the href attribute of an elementprint(link.get('href'))
Find children of an HTML element
Some websites just don’t want to be friends with your scripts. While it can be an absolute breeze to scrape and parse a website with clean, accurate class attributes, there are many cases where an HTML element will not have an attribute. This will require a different approach – we must target the parents and their children!
Don’t worry, it’s not as bad as it sounds. In an HTML page, you might’ve noticed that an element will have multiple other elements under it, such as paragraphs, tables, or lists. The one that holds them all together is called a parent, while the items under it are called children. Lucky for us, Beautiful Soup has a way of navigating through this structure, making reaching even the darkest crevices possible.
Let’s take a look at our web page in the developer tools. On the right sidebar are several links; if you inspect them, you can see that they’re structured as an unordered list without any attributes:
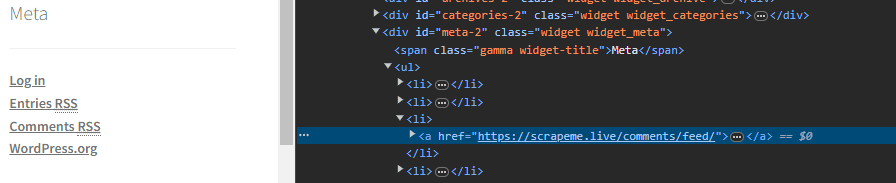
Say you want to get the Comments RSS link – how would you tell your script how to find it? Here’s how:
from bs4 import BeautifulSoupimport requestsurl = "https://scrapeme.live/shop/"response = requests.get(url)soup = BeautifulSoup(response.content, "html.parser")# Find a parent element with a unique attribute that is closest to what you're trying to target. In this case, widget_meta is the class name of the <div> element with several children without attributes.widget = soup.find(class_="widget_meta")# Target the <ul> first. It's the 2nd child of the widget_meta class <div>; therefore, we write a [2] to tell it's positionlist = widget.contents[2]# Next, find the <a> element with the href you're looking for. It's the 5th child of the <ul> - make sure to count the <a> element under the 2nd <li>, as it's an indirect child of <ul>.comments = list.contents[5]# Finally, we simply take the <a> directly with [0] and get the href attribute valuelink = comments.contents[0].get('href')print(link)
Scraping & parsing HTML data from a real-world website
While we’ve had fun in the playground, it’s time to enter the real world. That might sound scary, but the reality is that most actual websites function exactly like the one we used in our examples. They follow the same HTML structure, contain URLs, specific elements with identifiable attributes, etc. The key difference is that they protect themselves from scraping their data.
A website can track how many requests are made from a single IP address. Humans are usually slow, take their time, and read pages properly. A script doesn’t do that – it goes fast, gets what it needs, and moves to the next task. This behavior can be easily identifiable as your script will make multiple requests on your behalf and cause risks such as getting your IP blocked from accessing the website.
The solution? Proxy servers. A proxy server acts as an intermediary between you and your target, allowing you to make requests from an IP address different from your own. This allows you to create multiple requests, as they will appear as if they were coming from several separate IP addresses and are impossible to block or trace back to the source.
A popular target to scrape and parse data from is Amazon. It’s a vast marketplace with heaps of valuable information on products, purchases, pricing, reviews, and more data that can be incredibly valuable for any business or curious mind. Check out how to scrape Amazon product data and parse product titles, prices, and reviews.
Best practices
Knowledge is power; you can never know too much about data parsing. Here’re some valuable tips that you should keep in mind while writing parsing scripts:
- Many websites will employ anti-scraping and parsing measures to prevent you from sending too many requests from one IP address. Using proxies in your scripts eliminates this problem, as you’ll be able to make requests from multiple locations worldwide and ensure total anonymity of where the requests are coming from;
- A parsed result may not always be clean – therefore, it’s helpful to apply methods such as result.text.strip() that will return only string values without any extra spaces, symbols, HTML tags, or other extra nuisances that make your data look messy;
- Do you copy and paste all your parsed data from the Terminal into a notepad, pass it on to your data analysts, and wonder why they’re giving you a side-eye? Well, they can probably tell you why, and that’s because it’s always easier to work with data presented in structured CSV, XML, JSON, or similar files. Improve your code and have it write data into a new file instead of a Terminal;
- Make sure to follow the requirements inside a website’s robots.txt file. This file tells what pages can be web crawled and scraped and which shouldn’t be touched and left alone. Respect the robots!
- Some pages might not be easy to iterate in your script – they won’t have numbering in their links or follow a logical structure. Therefore, you might need to prepare an array of links and loop through them instead. Prepare a text file with all of the links and have your script read from it, make a request, parse the response, and go to the next link.
- A dynamic website can be harder to scrape, as it might not provide a full HTML response as soon as it is loaded. As more and more websites are being built with the help of JavaScript, this is becoming a more frequent occurrence. You’ll need to adjust your HTML parser script to have a slight delay or use headless browsers built for handling dynamic content.
Final thoughts
In this article, you’ve gained a basic understanding of the benefits of data parsing, how to use Beautiful Soup, and explored examples of how it can be used for parsing web information. We’ve only touched the basics, and there’re still many things you can expand your knowledge on. If you wish to continue your parsing journey, read the official Beautiful Soup documentation to learn about it more in-depth. You should also check out our fantastic proxy options to help you scrape the web without any risks or issues!
About the author

Zilvinas Tamulis
Technical Copywriter
A technical writer with over 4 years of experience, Žilvinas blends his studies in Multimedia & Computer Design with practical expertise in creating user manuals, guides, and technical documentation. His work includes developing web projects used by hundreds daily, drawing from hands-on experience with JavaScript, PHP, and Python.
Connect with Žilvinas via LinkedIn
All information on Smartproxy Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may belinked therein.


