How to Scrape Google News With Python
Keeping up with everything happening around the world can feel overwhelming. With countless news sites competing for your attention using catchy headlines, it’s hard to find what you need among celebrity tea and what the Kardashians were up to this week. Fortunately, there’s a handy tool called Google News that makes it easier to stay informed by helping you filter out the noise and focus on essential information. Let’s explore how you can use Google News together with Python to get the key updates delivered right to you.

What is Google News?
Google News is a powerful news aggregator that collects and organizes news articles from various news sources worldwide. It provides users with data tailored to their interests, location, and trending topics. By curating top stories and categorizing news results, Google News makes it easy to stay updated on current events. You can browse articles directly on the Google News web page or access specific categories, like business, technology, or sports, based on your interests.
What is Google News scraping?
Google News scraping is the process of extracting data from Google News using automated tools or scripts. This can involve collecting headlines, article summaries, publication dates, and other relevant news data from Google News search results. Businesses and researchers use Google News scrapers for market research, competitor analysis, and brand monitoring by tracking media coverage and industry trends.
Scraping can be done using Python libraries like Requests and BeautifulSoup to parse Google News URLs or with headless browsers like Playwright or Selenium to extract data from dynamic pages. It's also great to know that the Google News API and RSS feed URLs provide structured ways to access news sources without direct scraping.
Scraping Google News with Python
Let's get firsthand experience with scraping Google News. In this section, we'll go over the steps, from setting up your environment to getting information from the page no matter where it's located. Finally, we'll review some helpful tips and best practices so you can scrape responsibly and not end up on Google's naughty list.
Step 1: Setting up the environment
Before you start scraping, let’s make sure you have the right tools for the job. In this case, your essentials are Python and a few powerful libraries that will help you dig through the data with ease. Let’s get everything set up so you’re ready to extract information like a pro (or at least like someone who knows what they’re doing):
- Install Python. Make sure that you have the latest Python version should be installed on your machine. You can get it from the official downloads page.
- Install the required libraries. Requests and Beautiful Soup are the usual staples when it comes to scraping and parsing websites. We'll look into more advanced methods later, but for now, run this command in your terminal tool to install them:
pip install requests beautifulsoup4
3. Set up your IDE. Use a code editor or IDE, such as VS Code, PyCharm, or Jupyter Notebook, to write and execute your scripts.
Step 2: Sending a request to Google News
Once your environment is set up, the next step is to send an HTTP request to Google News to retrieve the latest headlines and articles. Using Python’s requests library, you can fetch Google News search results by working with the Google News URL directly.
Here's a simple example of how to make a request and extract the raw news data:
# Import the Requests libraryimport requests# Define the Google News URL with the search query and language, location, and edition parametersurl = "https://news.google.com/search?q=web+scraping&hl=en-US&gl=US&ceid=US:en"# Send the requestresponse = requests.get(url)# Print the HTML contentprint(response.text)
Above is a simple 4-line script to retrieve HTML data from a website. The parameters in the URL determine what results you'll receive:
Parameter
Name
Definition
q
query
The query that you'd usually enter into the search field to retrieve results.
hl
host language
Determines the language in which the news is displayed. It's written as an ISO language code.
gl
geographic location
Influences the news results based on the selected country. For example, US means the results are tailored for users in the United States.
ceid
country edition ID
Specifies the country and language edition of Google News.
The rest of the code simply makes an HTTP GET request to the target url, retrieves the data, and prints the content. To execute this script, enter the following command in your terminal:
python script-name.py
Step 3: Parsing the HTML with BeautifulSoup
Now that you’ve successfully retrieved the Google News HTML content, the next step is to parse it and extract useful information like headlines, article links, and publication dates. To do this, you’ll use BeautifulSoup, the most popular Python library for HTML parsing.
For now, let's only extract the article titles. If you use Inspect Element on the results page, after careful digging, you'll find that the article titles are located inside the <a> element with a class "JtKRv". Keep in mind that the name is dynamically generated, meaning that it could differ for you. Make sure to check the raw HTML contents yourself and find the correct class name.
With this information, you can use Beautiful Soup's find_all() method to get all elements that match the criteria. Here's the modified script from before that extracts only the titles from the results:
import requests# import Beautiful Soup for parsing datafrom bs4 import BeautifulSoup# Define the Google News URLurl = "https://news.google.com/search?q=web+scraping&hl=en-US&gl=US&ceid=US:en"# Send the requestresponse = requests.get(url)# Parse the HTML contentsoup = BeautifulSoup(response.text, "html.parser")# Find all article titles using the specified class nametitles = soup.find_all("a", class_="JtKRv")# Print the first 10 titlesfor title in titles[:10]:print(title.text)
Since there are a lot of results, there's a [:10] modifier at the end to only print the first 10 results. You can adjust or remove it entirely if needed. If you see a list of titles printed in your terminal, it means that the script works as intended.
Step 4: Handling pagination or load more
Scraping just the titles doesn't provide very valuable results. The real "meat" of information is found in the articles themselves, so you need a more intricate way of not only getting the titles but also navigating to web pages, finding specific content, and even rendering dynamic content if there is any. According to data by W3Techs, over 98.9% of websites use JavaScript. That means that there's a high likelihood that the website you're trying to scrape will contain rendered content that's not visible through traditional scraping methods.
To handle this, you'll need to use something called a headless browser – a browser that runs without a graphical user interface (GUI). This allows you to interact with web pages, execute JavaScript, and simulate user actions like scrolling, clicking, or navigating without the need for a visual display. Headless browsers, such as Playwright or Selenium, are perfect for scraping dynamic content that loads after the initial page load.
While Selenium has been the staple headless browser choice for many years, Playwright has made us fall in love with it for its simplicity, speed, and efficiency. Here's a quick way to get it set up and ready:
- Install Playwright. Run the following command to get the Playwright library in your Python environment. It allows you to use Playwright’s Python API to interact with browsers:
pip install playwright
2. Install the necessary browsers. Get the necessary browser binaries (Chromium, Firefox, and WebKit) that Playwright uses to automate browsers. Playwright needs these binaries to run browser automation tasks, but they're not included with the initial library installation:
python -m playwright install
3. Include Playwright in your script. Add a line at the start of your script to add Playwright and use its functionalities:
from playwright.sync_api import sync_playwright
That's all for basic setup. Now, let's go back and improve the code from before:
from playwright.sync_api import sync_playwrightfrom bs4 import BeautifulSoupdef scrape_google_news():with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()# Define the Google News URLurl = "https://news.google.com/search?q=web+scraping&hl=en-US&gl=US&ceid=US%3Aen"# Navigate to the pagepage.goto(url)# Wait for the "Accept All" button to appear and click it by text contentpage.wait_for_selector('text="Accept all"', timeout=10000) # Adjust timeout if neededpage.click('text="Accept all"')# Wait for the page to fully load after clicking the buttonpage.wait_for_timeout(5000) # Adjust if needed# Get the page contentcontent = page.content()# Close the browserbrowser.close()# Parse the HTML content with BeautifulSoupsoup = BeautifulSoup(content, "html.parser")# Find all article titlestitles = soup.find_all("a", class_="JtKRv")# Print the first 10 titlesfor title in titles[:10]:print(title.text)if __name__ == "__main__":scrape_google_news()
That's how our previous script looks like when rewritten in Playwright. While most lines perform the same process, one key difference added is the "Accept all" button click. If you run the script, you'll immediately see why – if Google News is accessed from a web browser for the first time, it requires the user to either accept or reject cookies. The script simply finds an element that contains the provided text and clicks that element.
Now for the real challenge – don't worry, it's not complicated! Let's say you want to access 10 websites from the Google News results page and search them whether the article contains the words "proxy" or "proxies." It's a good way to gauge how often people mention proxies when talking about web scraping. Here's the script:
from playwright.sync_api import sync_playwrightfrom bs4 import BeautifulSoupdef scrape_google_news():with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()# Define the Google News URLurl = "https://news.google.com/search?q=web+scraping&hl=en-US&gl=US&ceid=US%3Aen"# Navigate to the pagepage.goto(url)# Wait for the "Accept all" button to appear and click it by text contentpage.wait_for_selector('text="Accept all"', timeout=10000) # Adjust timeout if neededpage.click('text="Accept all"')# Wait for the page to fully load after clicking the buttonpage.wait_for_timeout(5000) # Adjust if needed# Get the page contentcontent = page.content()# Parse the HTML content with BeautifulSoupsoup = BeautifulSoup(content, "html.parser")# Find all article links (now using the correct class name "WwrzSb")links = soup.find_all("a", class_="WwrzSb")titles = soup.find_all("a", class_="JtKRv")proxy_count = 0 # Initialize counter for articles containing "proxy" or "proxies"total_count = 0 # Initialize counter for total articles scraped# Iterate over the linksfor title, link in zip(titles[:10], links[:10]):article_title = title.textarticle_url = link['href']# Ensure the URL is complete (Google News URLs can be relative)if article_url.startswith('./'):article_url = "https://news.google.com" + article_url# Navigate to the article pagepage.goto(article_url)# Wait for the page to fully loadpage.wait_for_timeout(5000) # Adjust if needed# Get the current full URL of the pagecurrent_url = page.url# Get the article contentarticle_content = page.content()# Parse the article content with BeautifulSouparticle_soup = BeautifulSoup(article_content, "html.parser")# Check if the article contains the keywords "proxy" or "proxies"article_text = article_soup.get_text().lower() # Get the text and convert to lowercasecontains_proxy = "proxy" in article_text or "proxies" in article_text# Print the title, URL, and whether the keyword is mentionedprint(f"Title: {article_title}")print(f"URL: {page.url}")print(f"Contains 'proxy' or 'proxies': {contains_proxy}")# Increment counterstotal_count += 1if contains_proxy:proxy_count += 1# Print the amount of URLs that contained the phrase and the number of total URLs scrapedprint(f"\n{proxy_count}/{total_count} URLs contained the phrases.")# Close the browserbrowser.close()if __name__ == "__main__":scrape_google_news()
Here's the breakdown of what Playwright was told to do:
- Load the Google News website.
- Click the "Accept all" button to accept cookies.
- Find the URL of the article by its class name.
- Find the title of the article by its class name.
- Add a counter from 0 to count mentions of specified phrases and links scraped.
- Iterate over the URLs and access each website.
- Find "proxy" or "proxies" phrases in the websites.
- Print the title, URL, and whether the phrases were found.
- Print the total number of mentions found and links scraped.
- Close the browser.
You should see the title, URL, and whether the phrases were printed in the terminal. As a final note, you can change the headless variable value to True to save resources and time, as graphically loading each website can be resource-intensive.
Step 5: Storing the data
Let's face it – the terminal isn't the best place to show data in a business meeting. The results should be printed in a file, such as CSV, XLSX, or TXT, for easy reading.
Here's one more adjustment to the code to print the data into a CSV file:
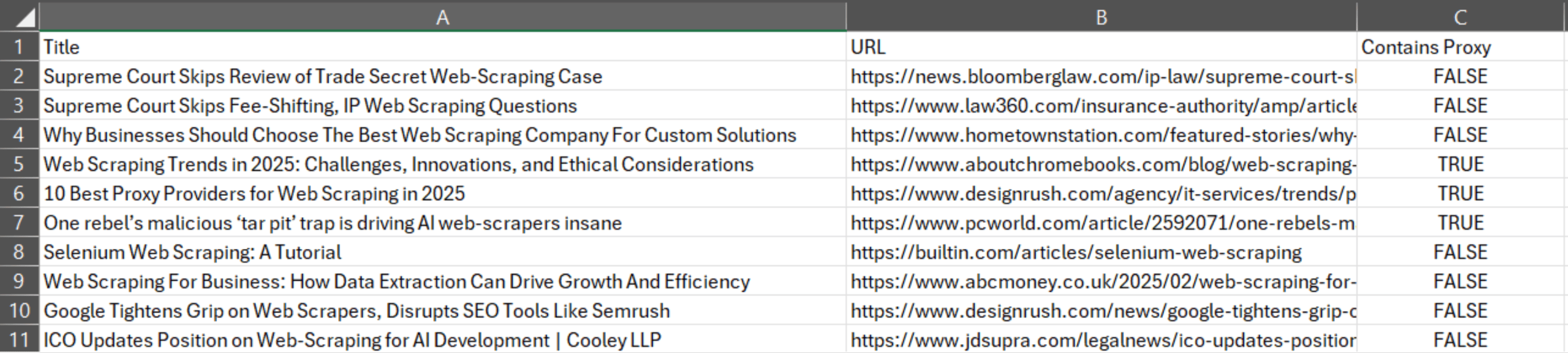
import csvfrom playwright.sync_api import sync_playwrightfrom bs4 import BeautifulSoupdef scrape_google_news():with sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()# Define the Google News URLurl = "https://news.google.com/search?q=web+scraping&hl=en-US&gl=US&ceid=US%3Aen"# Navigate to the pagepage.goto(url)# Wait for the "Accept all" button to appear and click it by text contentpage.wait_for_selector('text="Accept all"', timeout=10000) # Adjust timeout if neededpage.click('text="Accept all"')# Wait for the page to fully load after clicking the buttonpage.wait_for_timeout(5000) # Adjust if needed# Get the page contentcontent = page.content()# Parse the HTML content with BeautifulSoupsoup = BeautifulSoup(content, "html.parser")# Find all article links (now using the correct class name "WwrzSb")links = soup.find_all("a", class_="WwrzSb")titles = soup.find_all("a", class_="JtKRv")proxy_count = 0 # Initialize counter for articles containing "proxy" or "proxies"total_count = 0 # Initialize counter for total articles scraped# Open a CSV file for writingwith open('scraped_articles.csv', 'w', newline='', encoding='utf-8') as csvfile:fieldnames = ['Title', 'URL', 'Contains Proxy']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)# Write the header rowwriter.writeheader()# Iterate over the linksfor title, link in zip(titles[:10], links[:10]):article_title = title.textarticle_url = link['href']# Ensure the URL is complete (Google News URLs can be relative)if article_url.startswith('./'):article_url = "https://news.google.com" + article_url# Navigate to the article pagepage.goto(article_url)# Wait for the page to fully loadpage.wait_for_timeout(5000) # Adjust if needed# Get the article contentarticle_content = page.content()# Parse the article content with BeautifulSouparticle_soup = BeautifulSoup(article_content, "html.parser")# Check if the article contains the keywords "proxy" or "proxies"article_text = article_soup.get_text().lower() # Get the text and convert to lowercasecontains_proxy = "proxy" in article_text or "proxies" in article_text# Write the article data to the CSV filewriter.writerow({'Title': article_title, 'URL': page.url, 'Contains Proxy': contains_proxy})# Print the data to the terminalprint(f"Title: {article_title}")print(f"URL: {page.url}")print(f"Contains 'proxy' or 'proxies': {contains_proxy}")print()# Increment counterstotal_count += 1if contains_proxy:proxy_count += 1# Print the amount of URLs that contained the phrase and the number of total URLs scrapedprint(f"\n{proxy_count}/{total_count} URLs contained the phrases.")# Close the browserbrowser.close()if __name__ == "__main__":scrape_google_news()
The key difference here is the imported csv library. It opens a CSV file for writing, and the data that's been scraped is then stored in the file, alongside printing it in the terminal. Once the scraping task is complete, you should see a scraped_articles.csv file in your project directory:
Step 6: Avoiding blocks and CAPTCHAs
When scraping Google News, automated scripts often face challenges because the site has protections to detect and block high volumes of traffic from a single source. This can happen when there are repetitive requests, sudden spikes in activity, or unusual browsing patterns, leading to temporary or permanent IP bans.
CAPTCHAs are another obstacle. They require complex tasks that only humans can solve, such as identifying distorted text or objects in images. These challenges can stop your script from running. To avoid CAPTCHAs and minimize detection, it's essential to use proper IP rotation and respect rate limits.
If you're experiencing issues like incorrect or missing data, adding proxies to your script will help by ensuring requests come from different locations, making them harder to block:
import csvfrom playwright.sync_api import sync_playwrightfrom bs4 import BeautifulSoupdef scrape_google_news():# Proxy configurationproxy_config = {"server": "endpoint:port", # Proxy server and port only"username": "user","password": "pass"}with sync_playwright() as p:browser = p.chromium.launch(headless=False, proxy=proxy_config)page = browser.new_page()# Define the Google News URLurl = "https://news.google.com/search?q=web+scraping&hl=en-US&gl=US&ceid=US%3Aen"# Navigate to the pagepage.goto(url)# Wait for the "Accept all" button to appear and click it if foundtry:accept_button = page.wait_for_selector('text="Accept all"', timeout=5000) # Adjust timeout if neededif accept_button:page.click('text="Accept all"')except:print("No 'Accept all' button found, continuing...")# Wait for the page to fully load after clicking the buttonpage.wait_for_timeout(5000) # Adjust if needed# Get the page contentcontent = page.content()# Parse the HTML content with BeautifulSoupsoup = BeautifulSoup(content, "html.parser")# Find all article links (now using the correct class name "WwrzSb")links = soup.find_all("a", class_="WwrzSb")titles = soup.find_all("a", class_="JtKRv")proxy_count = 0 # Initialize counter for articles containing "proxy" or "proxies"total_count = 0 # Initialize counter for total articles scraped# Open a CSV file for writingwith open('scraped_articles.csv', 'w', newline='', encoding='utf-8') as csvfile:fieldnames = ['Title', 'URL', 'Contains Proxy']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)# Write the header rowwriter.writeheader()# Iterate over the linksfor title, link in zip(titles[:10], links[:10]):article_title = title.textarticle_url = link['href']# Ensure the URL is complete (Google News URLs can be relative)if article_url.startswith('./'):article_url = "https://news.google.com" + article_url# Navigate to the article pagepage.goto(article_url)# Wait for the page to fully loadpage.wait_for_timeout(5000) # Adjust if needed# Get the article contentarticle_content = page.content()# Parse the article content with BeautifulSouparticle_soup = BeautifulSoup(article_content, "html.parser")# Check if the article contains the keywords "proxy" or "proxies"article_text = article_soup.get_text().lower() # Get the text and convert to lowercasecontains_proxy = "proxy" in article_text or "proxies" in article_text# Write the article data to the CSV filewriter.writerow({'Title': article_title, 'URL': page.url, 'Contains Proxy': contains_proxy})# Print the data to the terminalprint(f"Title: {article_title}")print(f"URL: {page.url}")print(f"Contains 'proxy' or 'proxies': {contains_proxy}")print()# Increment counterstotal_count += 1if contains_proxy:proxy_count += 1# Print the amount of URLs that contained the phrase and the number of total URLs scrapedprint(f"\n{proxy_count}/{total_count} URLs contained the phrases.")# Close the browserbrowser.close()if __name__ == "__main__":scrape_google_news()
There are two key adjustments here:
- Added proxy configuration information. You're going to need the username, password and endpoint information for the proxy you're using. You can easily get them from the Smartproxy Dashboard.
- Added a conditional check for the "Accept all" button. Since you're using proxies, it's not guaranteed that you'll need to click anything to accept cookies.
That's the final adjustment for the Google News web scraping script. You now have a working script that can scrape any Google News search result page, access the news article URLs, find specific data, and present it in an easy-to-read format.
Best practices for Google News data scraping
Keep these practices in mind when scraping Google News to achieve the best results:
- Respect the robots.txt file. Always check the Google News robots.txt file to understand which pages can be scraped and follow its guidelines to avoid violations.
- Limit frequency. Reduce request rates and introduce delays between scrapes to prevent triggering anti-bot mechanisms and ensure sustainable data access.
- Use rotating proxies. Implement a rotating proxy system to distribute requests across multiple IPs, minimizing the risk of blocks and bans.
- Update your script regularly. Modify your scraping script to adapt to website structure changes and improve efficiency over time.
- Leverage RSS feeds. Utilize RSS feeds as a reliable and structured way to collect news data without excessive web scraping.
Wrap-up
Scraping Google News with Python is like having your custom news feed built exactly the way you want it. You’ve learned how to extract news titles, navigate to full articles, and even render dynamic content when needed. But here’s the challenge: without proxies, Google will stop you in your tracks before you can grab your next headline. That's why you must ensure to rotate IPs with Smartproxy's proxy solutions, respect the rules, and keep your scraper stealthy. Now, put your skills to work and stay ahead of the news like never before!
About the author

Zilvinas Tamulis
Technical Copywriter
A technical writer with over 4 years of experience, Žilvinas blends his studies in Multimedia & Computer Design with practical expertise in creating user manuals, guides, and technical documentation. His work includes developing web projects used by hundreds daily, drawing from hands-on experience with JavaScript, PHP, and Python.
Connect with Žilvinas via LinkedIn
All information on Smartproxy Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may belinked therein.