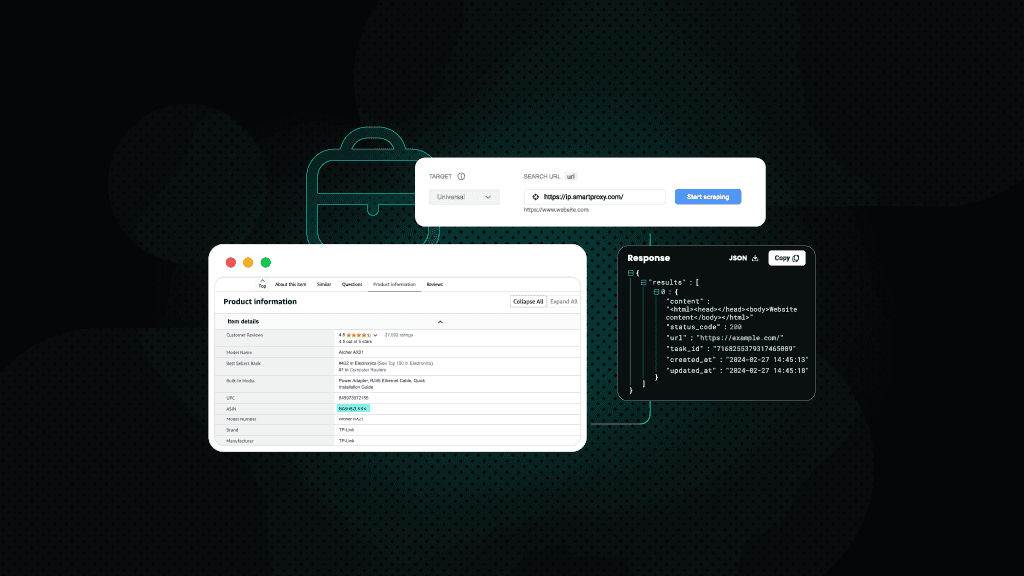
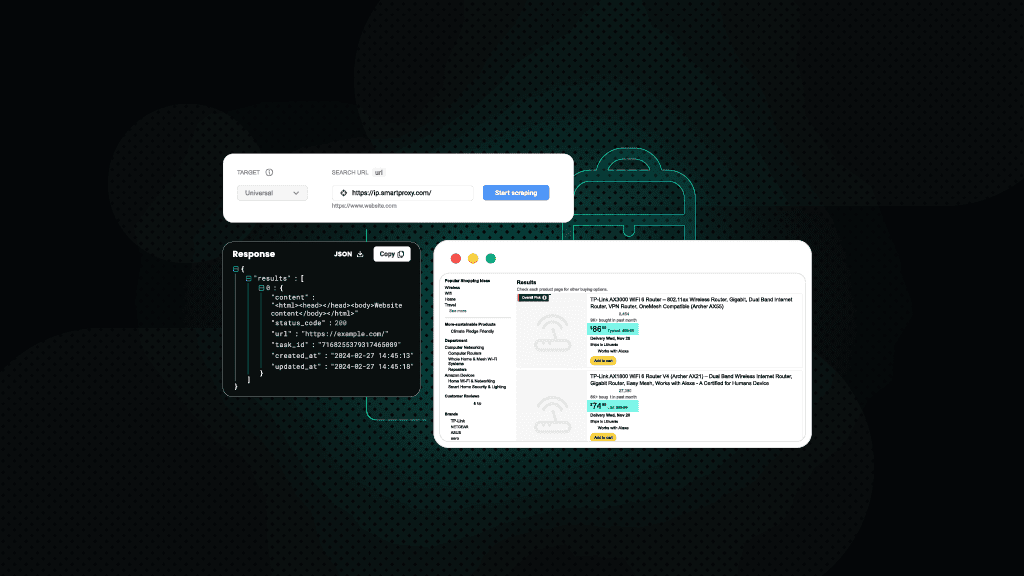
What Is Web Scraping? A Complete Guide to Its Uses and Best Practices
Web scraping is a powerful tool driving innovation across industries, and its full potential continues to unfold with each day. In this guide, we'll cover the fundamentals of web scraping – from basic concepts and techniques to practical applications and challenges. We’ll share best practices and explore emerging trends to help you stay ahead in this dynamic field.
What is web scraping?
Web scraping is the process of extracting data from websites using automated tools, like web scraper, or scripts. It enables users to gather large amounts of structured or unstructured information from the web quickly and efficiently. This data is then transformed into usable formats for further analysis or applications.
In data analytics, web scraping provides real-time access to valuable insights, fueling accurate decision-making. For artificial intelligence and machine learning, scraped data serves as essential training material for algorithms, enabling these technologies to grow smarter and more effective.
Businesses leverage web scraping for automation, streamlining tasks like price monitoring, market research, and lead generation. This significantly reduces manual work while increasing operational efficiency. In essence, web scraping has become a cornerstone of digital innovation.
What’s the difference between web scraping and screen scraping?
Web scraping and screen scraping are distinct processes, though they’re sometimes confused due to their overlapping goal of extracting information.
Web scraping focuses on extracting structured data from the HTML of a website. It interacts with a website’s underlying code, parsing the content to collect data elements like text, images, or links. Web scraping is designed to handle vast amounts of data systematically and is used for tasks like data aggregation, analysis, and integration into databases.
Screen scraping, on the other hand, captures data based on what is visually rendered on a screen. It mimics user interactions, extracting text and images exactly as they appear to human users. This method is often less efficient and more error-prone, as it relies on the layout and display of information rather than the underlying structure.
In short, web scraping delves into the structural backbone of websites for precise, large-scale data extraction, while screen scraping relies on surface-level visual data, making it less versatile and more suited for niche applications.
How does web scraping work?
So, we know that web scraping is an automated process, but what happens during it? Here’s the series of steps that enable data extraction from online sources:
- Sending an HTTP request. The process begins by sending an HTTP request (usually GET or POST) to a webpage. This request asks the server to deliver the content of the page or an API response.
- Retrieving the response. Upon receiving the request, the server returns a response that contains the HTML source code or API data. This serves as the raw material for scraping.
- Parsing and extracting data. The retrieved data is then parsed using specialized tools or libraries. Specific elements such as titles, prices, or links are extracted based on the structure of the webpage or the API’s data format.
Web scraping depends heavily on the right tools and technologies to make it effective. These tools handle everything from parsing HTML to simulating user behavior and overcoming restrictions. Here are the core components that power modern web scraping:
- Libraries. Popular libraries like BeautifulSoup, Scrapy, and Puppeteer are the backbone of web scraping. BeautifulSoup excels at parsing HTML and XML, while Scrapy provides a framework for building large-scale scraping projects. Puppeteer, a Node.js library, is perfect for handling dynamic or JavaScript-heavy content.
- Headless browsers. Tools like Puppeteer and Playwright allow for browser automation, simulating real user behavior to access complex websites. These are particularly useful for sites that dynamically load content or require user interaction.
- Proxies. Proxies are essential for bypassing IP bans, rate limits, and geo-restrictions. They route requests through different IPs to avoid detection or access region-specific content.
What is the process of web scraping?
To successfully extract data from websites, web scraping follows a structured, step-by-step approach. Each stage is designed to handle specific tasks, from identifying the target data to automating the entire process for consistent and efficient results:
- Identifying the target website. Determine the specific web pages and data you want to scrape. Clearly define your objective, whether it’s extracting product prices, customer reviews, or other relevant information.
- Inspecting the web page. Use browser developer tools to analyze the HTML structure of the target webpage. Identify the tags, classes, or IDs that contain the desired data.
- Sending an HTTP request. Utilize tools or libraries (e.g., requests in Python) to send an HTTP request to the target webpage, fetching its content or API response.
- Retrieving the response. Once the request is processed, capture the server’s response, which often includes the HTML or JSON data required for extraction.
- Parsing the HTML. Use libraries like BeautifulSoup (Python) or Cheerio (JavaScript) to parse the HTML DOM. Navigate through the structure and isolate the specific data elements you need.
- Data cleaning and processing. Clean and standardize the extracted data using tools like Pandas or Regex. Ensure the data is structured, consistent, and ready for analysis or storage.
- Storing data. For easy retrieval and further use, save the cleaned data in your preferred format, such as CSV or JSON, or put it directly into a database.
- Automating the process. Create scripts or schedule tasks using tools like Cron (Linux), Task Scheduler (Windows), or launchd (macOS) to automate scraping and keep the data updated periodically.
Types of web scrapers
Web scrapers come in many forms, each suited for specific scenarios. Here's a breakdown of common types based on deployment, hosting, functionality, interface, and automation level, along with their pros and cons:
Self-built vs. pre-built
- Self-built. Custom scripts created with tools like Python and BeautifulSoup offer unmatched flexibility for specialized tasks. For instance, a Python script can scrape product prices with complete control over the process. However, they require coding expertise and time to develop.
- Pre-built. Ready-made tools, such as no-code platforms, are user-friendly and quick to set up, ideal for straightforward tasks like gathering academic metadata. On the downside, they lack customization and can be costly for advanced features.
Cloud-based vs. local
- Cloud-based. Online scrapers like Scrapy Cloud are scalable and accessible from anywhere, perfect for large-scale projects, such as extracting eCommerce reviews globally. The drawbacks include their reliance on internet connectivity and subscription fees.
- Local. Installed on personal machines, local scrapers offer full control and no recurring costs, which is excellent for small-scale tasks like collecting satellite imagery metadata with MATLAB. They're typically resource-intensive and less scalable.
General-purpose vs. specialized
- General-purpose. Tools like Selenium and Playwright handle a variety of tasks, including JavaScript-heavy content, but may require complex configurations for niche tasks. For example, Playwright can scrape dynamic web applications with advanced authentication.
- Specialized. Built for specific industries, these scrapers are optimized for tasks like real estate listings or financial data. A cryptocurrency trading scraper excels at targeted tasks but lacks flexibility for broader applications.
Browser extensions vs. software-based
- Browser extensions. Tools like Web Scraper for Chrome are easy to use and perfect for small tasks, such as comparing prices on travel booking sites. However, they're limited in scalability and functionality.
- Software-based. Standalone tools like Scrapy and Apache Nutch handle advanced, large-scale projects, such as archiving academic web resources. However, they require installation and have a steeper learning curve.
Manual vs. fully automated
- Manual. User-driven tools are great for one-off or irregular tasks, offering more control. For example, a researcher manually running a Python script to gather election sentiment data ensures precision but requires significant time.
- Fully automated. Once configured, automated scrapers operate independently using scheduling or bots. A machine learning pipeline that updates daily sentiment trends is efficient but demands complex setup and monitoring.
What is web scraping used for?
Web scraping is an indispensable tool for its wide range of applications across industries. Here are some of the most common use cases:
Market research
Web scraping helps businesses gather data on competitors, consumer behavior, and industry trends. Companies can make informed strategic decisions by analyzing information like product reviews, market share, and emerging trends. It provides real-time, large-scale data that would otherwise take significant time to collect manually.
Business automation
Many repetitive business tasks, such as monitoring inventory levels, updating customer data, or tracking website changes, can be automated with web scraping. This reduces the need for manual intervention, saving time and resources while ensuring processes remain error-free.
Lead generation
Web scraping is an effective tool for generating leads by extracting contact details, such as email addresses or phone numbers, from websites. It enables sales and marketing teams to build targeted lists of prospects based on industry, location, or other criteria, streamlining the process of finding potential clients.
Price tracking
Scraping eCommerce websites for pricing information allows businesses to monitor competitors' prices in real time. This data is crucial for adjusting pricing strategies, offering competitive deals, or identifying trends in product demand.
Sentiment analysis
By scraping reviews, comments, or social media posts, companies can analyze customer sentiment about their products, services, or brand. This feedback helps identify areas of improvement, measure customer satisfaction, and track the impact of marketing campaigns. Sentiment analysis provides valuable insights into consumer opinion at scale.
Real estate trends
Real estate professionals use web scraping to track property listings, prices, and market trends. Collecting data from property websites allows them to analyze regional pricing patterns, property availability, and market demand. This enables more accurate forecasting and better-informed investment decisions.
What are the most common web scraping challenges?
Web scraping comes with its own set of challenges that can complicate the process. Overcoming them requires a combination of the right tools and careful planning. Here are some of the most common hurdles:
Handling dynamic content and JavaScript-heavy websites
Many modern websites rely on JavaScript to load content dynamically, meaning the data isn’t available in the initial HTML response. Scraping these sites requires specialized tools, such as headless browsers (e.g., Puppeteer or Playwright), to render and extract the dynamically loaded content. This adds complexity and can slow down the scraping process.
Dealing with anti-scraping mechanisms
Websites often deploy anti-scraping tools to protect their data. Techniques like CAPTCHAs, IP rate limiting, and bot detection can block scraping activities. Overcoming these barriers requires the use of proxies, user-agent rotation, and CAPTCHA-solving services, but these solutions can increase the cost and complexity of scraping.
Data quality and accuracy issues
Scraping raw data from websites can result in inconsistencies, duplicates, or incomplete records due to changes in website structure or errors during extraction. Ensuring high-quality, accurate data often requires implementing robust error handling, regular monitoring, and thorough data cleaning techniques, which add additional steps to the process.
Website structure changes
Websites frequently update their layouts, which can break scraping scripts. Maintaining scrapers requires regular updates to adapt to structural changes, making the process more time-consuming and resource-intensive.
Scalability and performance
As scraping projects grow in size, scaling becomes a challenge. Scraping thousands of pages can strain resources, require more bandwidth, and increase the likelihood of detection. Efficiently handling large-scale scraping requires optimized scripts, distributed systems, and load balancing.
Server overloads and blocking
Scraping too many pages in a short time can overload the target website’s servers, resulting in temporary blocks or server errors. Scrapers must implement rate limiting to avoid such issues while ensuring consistent data collection.
Best practices for effective web scraping
To maximize efficiency, it’s essential to follow best practices when conducting web scraping. Here’s how to approach web scraping responsibly and effectively:
- Implement efficient data extraction methods. Use targeted selectors (tags, classes, IDs) to extract only necessary data. Minimize processing time by avoiding unnecessary content downloads, reducing server strain, and improving performance.
- Ensure data accuracy and validation. Implement validation techniques to clean scraped data. Use regex patterns or schema checks to eliminate duplicates and irrelevant information, ensuring accurate and consistent output.
- Manage request rates to avoid server overload. Apply rate-limiting techniques with random delays between requests. Prevent server overload and avoid IP bans by practicing polite scraping.
- Use proxies and user-agent rotation. Rotate proxies and user-agent strings to distribute requests and mimic genuine browser behavior. This reduces detection risks and bypasses IP-based restrictions.
- Monitor and adapt to website changes. Regularly monitor target websites for structural changes. Keep scraping scripts updated to maintain uninterrupted data extraction.
- Handle dynamic content with the right tools. Use headless browsers to scrape JavaScript-heavy websites, managing complex interactions and AJAX-loaded content effectively.
- Automate and scale thoughtfully. Utilize scheduling tools and distributed computing solutions. Scale scraping projects thoughtfully, monitoring performance to prevent resource overload.
Future trends in web scraping
Web scraping is constantly evolving alongside advancements in technology. The future of web scraping is marked by a combination of technological innovation, ethical responsibility, and a shift toward collaborative data exchange. Here’s a look at the key trends redefining its potential:
AI-driven adaptive scraping
The integration of artificial intelligence is transforming web scraping into a smarter, more adaptive process. AI-powered scrapers can now detect changes in website structures, adapt their strategies dynamically, and even predict patterns in data. Machine learning algorithms enable scrapers to identify and extract complex relationships within datasets, making the process more efficient and less prone to disruptions caused by website updates. This evolution is paving the way for faster, more precise, and automated scraping solutions.
Automation beyond scraping
The future of web scraping lies in integrating it with broader automation pipelines. By combining scraping with data processing, machine learning, and visualization tools, businesses can create end-to-end workflows that go beyond just data collection. These intelligent systems will analyze and act on scraped data in real time, enabling more dynamic decision-making and operational efficiency.
Advancements in anti-scraping technologies
As scraping capabilities improve, so do the defenses against them. Websites are increasingly employing advanced anti-scraping mechanisms such as AI-driven bot detection, behavioral analysis, and more sophisticated CAPTCHAs. This creates a constant tug-of-war between scrapers and website security.
Cloud-based scraping for scalability
Cloud-based scraping solutions are gaining momentum, offering scalability, distributed processing, and reduced resource dependencies. As businesses demand faster and larger-scale data collection, cloud platforms enable scrapers to handle massive datasets efficiently while maintaining compliance with rate limits and other restrictions. This trend is likely to accelerate as cloud computing becomes more cost-effective.
The rise of no-code and low-code scraping tools
No-code and low-code platforms are revolutionizing web scraping by making it accessible to non-technical users. These tools, often integrated into scraping APIs, eliminate the need for technical expertise, custom scraper development, or proxy management. With advanced features like dynamic content scraping and API integration, they enable quick access to large datasets, empowering a wider audience to leverage web scraping for diverse use cases. Ready-made scrapers come standard with all our Scraping APIs, available with a 7-day free trial.
Final thoughts
Web scraping offers immense value for tasks like market research, automation, sentiment analysis, and many other purposes. As technologies evolve and data becomes increasingly critical, mastering data scraping techniques is key to maintaining a competitive edge in an information-driven world. We hope you'll take the ideas we've discussed here and put them into practice, transforming raw web data into meaningful, actionable insights.
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Smartproxy Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may belinked therein.