



Python Pandas Tutorial for Beginners
Pandas, both the cuddly animals and the Python library, are known for their efficiency – while one munches through bamboo, the other helps you munch through data. Pandas in Python is an amazing data analysis and manipulation tool offering powerful data structures and functions that make handling data a breeze. With Pandas by your side, your data will be as organized as a panda's daily schedule of eating and napping!

What is Pandas in Python?
Pandas (derived from panel data) is a powerful Python library for data manipulation and analysis, providing easy-to-use data structures that efficiently handle structured data. Some of its main features include:
- DataFrame and Series. Pandas uses the concept of Series (1D) and DataFrame (2D) for its data structures, which make data manipulation and analysis straightforward and intuitive.
- Data alignment. Automatically aligns data across different indexes when performing operations, ensuring consistent and accurate results.
- Data cleaning. Pandas provides the tools to handle missing data and duplicates and solve other common issues, so you can be sure you’ll never work with messy datasets.
- Group By functionality. Enables powerful data aggregation and transformation by grouping data based on specific criteria.
- Integration with other libraries. Pandas seamlessly integrates with other popular libraries, such as NumPy or Matplotlib, allowing enhanced numerical computations and visualizations.
What is Python Pandas used for?
Ask any data scientist about what they use for data analysis and manipulation, and many of them will recommend or have at least heard of Pandas. It’s a powerful industry-standard tool that’s used for various cases:
- Cleaning and preparing data. Pandas is extensively used to clean, transform, and prepare data for analysis. You can handle missing data, filter by rows or columns, merge multiple datasets, or apply functions to manipulate data into usable formats.
- Data analysis. Pandas allow you to calculate statistics, aggregate data, and perform operations like grouping and pivoting, which are essential for summarizing and understanding large datasets. It helps quickly generate data insights, such as finding trends, correlations, or outliers.
- Data aggregation. Pandas is used to group and aggregate data to summarize information based on specific criteria. This is useful for analyzing patterns over time, such as summarizing sales data by month, calculating the average value of transactions per customer, or aggregating data to find total counts or sums within specific categories.
Pandas is widely used across various industries worldwide, including finance, healthcare, eCommerce, logistics, marketing, and more. It plays a crucial role in analyzing diverse datasets, such as stock prices, patient records, purchasing patterns, shipment details, and advertising performance, making it a versatile tool regardless of your field.
How to install Pandas in Python
Without further ado, let’s get started with Pandas and see its powerful capabilities ourselves. First, you’ll need to make sure you’ve got Python installed on your computer. Next, you’ll want to install the Pandas library using one of the methods below.
Installing Pandas with pip
The pip package installer is the simplest way to install Python packages. You can use it to install Pandas by simply running the following command in your terminal tool:
pip install pandas
After a short delay, Pandas will be installed on your machine.
Installing Pandas with Anaconda
If you aren’t familiar with Python, the easiest way to install Pandas and other useful data analytics packages is with Anaconda. It comes preinstalled with all the libraries you need, including Pandas.
For more experienced developers, it’s recommended to download Miniconda. It allows you to create a minimal, self-contained Python installation that isn’t as big as Anaconda. After you download it, you can then use the package manager to install only the packages you need:
conda install -c conda-forge python pandas
Running a virtual environment
Running Pandas in a virtual environment is recommended. You can use the default venv module included with Python 3.3 and later. Activate it by running the following command:
python3 -m venv name_of_your_env
Importing data in Python using Pandas
First, create a Python script file (.py). You can run this script by navigating to the directory in your terminal tool and running the following command:
python your_file.py
To start working with data, you’ll need, well, data. Luckily, Pandas supports many different file formats, and you can easily import any of them using very simple and short commands. If you need an example data file, you can download one at the start of each section.
Place the file in the same directory as your Python script file. If the data file is placed elsewhere, enter the full path to the file.
Importing a CSV file
You can import a CSV file into Pandas with the following method:
import pandas as pddf = pd.read_csv('zoo_animals.csv')
Importing a text file
You can import a text file into Pandas with the following method:
import pandas as pddf = pd.read_csv('zoo_animals.txt', delimiter='\t')
The example text file uses a tab delimiter ('\t'), but you can also use comma (','), space (' '), semicolon (';'), and pipe ('|') options by setting the delimiter value accordingly.
Importing an Excel file
You can import an Excel file into Pandas with the following method:
import pandas as pddf = pd.read_excel('zoo_animals.xlsx')
Importing a JSON file
You can import a JSON file into Pandas with the following method:
import pandas as pddf = pd.read_json('zoo_animals’.json')
Viewing and selecting data with Pandas DataFrame
As every anxious developer, you’ll want to check whether the data you imported actually appears. Fear not, as we’ll dive into ways how to check and view data through simple functions.
View all data
The most simple method to view the entire table is to simply print the df element. It will display the table in its entirety:
print(df)
Viewing data using .head() and .tail()
Two more straightforward methods are the .head() and .tail(). As the name suggests, these will show the dataset's first or last 5 rows by default. You can enter a custom number of rows instead, too. For instance, let’s print the first 3 rows of our example file:
print(df.head(3))
Here’s the printed result:
Animal Age Habitat Weight (kg)0 Panda 5 Forest 1001 Elephant 10 Savannah 54002 Giraffe 7 Savannah 800
To print the last 3 rows, replace .head() with .tail(). You can also enter a different custom value to get more or less results.
Viewing data using .describe()
The .describe() method provides statistics for numerical columns. Using it without any additional parameters provides the number of items, mean value, standard deviation, minimum and maximum values, and percentiles. You can read about its customizability in more depth in the official documentation.
print(df.describe())
Result:
Age Weight (kg)count 10.000000 10.000000mean 6.900000 736.800000std 3.842742 1654.753812min 2.000000 3.00000025% 4.250000 88.75000050% 6.500000 175.00000075% 8.750000 340.000000max 15.000000 5400.000000
Viewing data using .info()
Pandas's .info() method concisely summarizes a DataFrame, giving you an overview of its structure and contents. It’s particularly useful for understanding the types of data within your DataFrame and checking for missing values.
print(df.info())
Here’s an example result of what it can provide:
<class 'pandas.core.frame.DataFrame'>RangeIndex: 10 entries, 0 to 9Data columns (total 4 columns):# Column Non-Null Count Dtype--- ------ -------------- -----0 Animal 10 non-null object1 Age 10 non-null int642 Habitat 10 non-null object3 Weight (kg) 10 non-null int64dtypes: int64(2), object(2)memory usage: 452.0+ bytes
- RangeIndex shows the range of the index, indicating how many rows the DataFrame has;
- The table shows column names, amount of non-null values in a column, and the data type of the column;
- Memory usage provides information on the memory usage of the DataFrame, which is useful for large datasets.
Viewing columns using .columns
The .columns attribute in Pandas is used to access the column labels of a DataFrame. It returns the names of all the columns in the DataFrame.
print(df.columns)
Output:
Index(['Animal', 'Age', 'Habitat', 'Weight (kg)'], dtype='object')
You can also use this method to perform all sorts of operations on the columns. For example, you can check if the column exists:
if 'Age' in df.columns:print("The 'Age' column exists.")
Selecting rows using .loc[] and .iloc[]
.loc[] and .iloc[] are used to select rows and columns from a DataFrame to view or edit row data. They both perform a similar job, but the approach to how they select data is slightly different. Let’s see how.
Using .loc[] (label-based indexing), you can select data by label or a boolean array. In our example file, let’s use it to find all rows that contain animals whose habitats are 'Savannah':
giraffe_row = df.loc[df['Habitat'] == 'Savannah']print(giraffe_row)
Output:
Animal Age Habitat Weight (kg)1 Elephant 10 Savannah 54002 Giraffe 7 Savannah 8003 Lion 4 Savannah 190
Using .iloc[] (integer-based indexing), you can select data by position – simply enter the number of the row you want to find. Remember the zero-based numbering in Python, so the row you want to find will always be +1 higher. Here’s how you’d print the third row of your dataset:
third_row = df.iloc[2]print(third_row)
Output:
Animal GiraffeAge 7Habitat SavannahWeight (kg) 800Name: 2, dtype: object
Selecting columns
The process of selecting columns is very similar to the above, with slightly different syntax. To select a specific column, use the .loc[] method with a colon as the first indexer. This signifies that the first indexer should select all rows and the second only the 'Animal' column:
animal_column = df.loc[:, 'Animal']print(animal_column)
Output:
0 Panda1 Elephant2 Giraffe3 Lion4 Zebra5 Kangaroo6 Penguin7 Tiger8 Gorilla9 FlamingoName: Animal, dtype: object
The .iloc[] variant is pretty much the same, but instead of entering a specific name, simply enter the numerical index value of a column:
df.iloc[:, 2] # Selects all rows and column 3
The methods provided are just simple examples of what Pandas can do with just a few lines of code. Read here if you’re interested in more specific ways of indexing and selecting data.
Modifying row data with .loc[] and .iloc[]
Now that you’ve learned how to find what you need in a dataset let’s learn ways to modify it. It’s really quite simple – you just need to use the same .loc[] and .iloc[] methods and assign a new value to the extracted row.
Let’s say you want to change the weight value for the 'Penguin' row because it ate too much fish and gained weight. To do that, use the .loc[] method to match the 'Animal' column to the 'Penguin' row and set the 'Weight' column to a new value:
df.loc[df['Animal'] == 'Penguin', 'Weight (kg)'] = 40
You can perform a similar operation with .iloc[] by specifying the row and column you want to edit:
df.iloc[6, 3] = 40 # 7th row, 4th column
Once you’re finished, remember that all the changes aren’t made directly to the imported file but stored in memory. To print the result, you’ll need to use the .to_csv() or an equivalent file method:
df.to_csv('zoo_animals.csv', index=False)
Modifying columns with DataFrame
Knowing how to change values inside your data is useful, but what if you’re not happy with the structure? Great news because Pandas allows you to perform data manipulation and modify how it appears. Let’s take a look at a few ways how you can play around with columns.
Adding a column
You can add a column by assigning a new value or a series of values to a new column name. There are several ways to do it, but here are a few main methods with examples:
- Add a column with a constant value. Create a column and set all its values to the same;
df['Endangered'] = 'Yes'
- Add a column based on existing columns. Add a new column that is the sum of another two columns;
df['Age_Weight_Sum'] = df['Age'] + df['Weight (kg)']
- Add a column with conditional values. Mark animals as 'Heavy' if their weight is over 300 kg.
df['Weight_Category'] = df['Weight (kg)'].apply(lambda x: 'Heavy' if x > 300 else 'Light')
Dropping a column
If you find that a column is no longer useful, you can .drop() it in the trash. Or toss it gently on the floor, whatever your definition of drop is. Either way, it’s going to disappear off the table.
To drop a single column, enter the following:
df = df.drop('Weight (kg)', axis=1)
If you want to drop multiple columns, you’ll have to specify each of their names:
df = df.drop(['Age', 'Habitat'], axis=1)
If you’re not sure what axis=1 stands for, it simply tells Pandas to drop a column. If you wanted to drop a row, you’d write the row name with axis=0 instead. This little detail is useful when both column and row value names match, and you need to be specific about which one to drop.
Renaming a column
Renaming columns in Pandas can be done using the .rename() method or by directly modifying the columns attribute. Here’s how you can do it:
df = df.rename(columns={'Animal': 'Species'})
Filtering by column
Filtering a DataFrame by a column in Pandas involves selecting rows that meet certain conditions based on the values in a specific column. Here are a few scenarios:
Filter rows where the habitat is 'Savannah':
filtered_df = df[df['Habitat'] == 'Savannah']
Filter rows where the 'Age' column is more than 5:
filtered_df = df[df['Age'] > 5]
Filter rows where the 'Animal' is either 'Panda' or 'Lion':
filtered_df = df[df['Animal'].isin(['Panda', 'Lion'])]
Sorting by column names
You can use the .sort_values() method to sort your DataFrame by one or more columns. Here’s how you can sort by the 'Weight (kg)' column in descending order:
df_sorted = df.sort_values(by='Weight (kg)', ascending=False)
By default, Pandas will sort in ascending order, so you don’t need to write an additional parameter if you want to do so instead.
Grouping data with the .groupby() function
The .groupby() function in Pandas is used to group data based on one or more columns and then perform aggregate operations on those groups. It’s useful for summarizing and analyzing data by categories.
The function primarily splits data into groups based on the values of the specified columns. It then applies an aggregation and combines the result as a new DataFrame. Here are a few of the more common aggregations that can be performed:
- .mean(). Computes the mean of each group;
- .sum(). Computes the sum of each group;
- .count(). Counts the number of non-null values in each group;
- .min() / .max(). Computes the minimum or maximum value in each group.
Grouping data by a single column
To group data by a single column, you must pick a column and pair it with an aggregation function. A single column might not provide enough data needed for sensible results, so it’s recommended to always group by at least 2 columns. Here’s a way to group by a single column:
grouped_count = df.groupby('Habitat').count()
The numbers tell you how many rows of data exist for each habitat in your DataFrame. While not entirely useful, it can be a good way to check if any of the rows are missing data.
Grouping data by multiple columns
Do you want to know which habitat has the heaviest animals? If you promise not to use this data for fat-shaming them, here’s the secret formula for how to do that:
grouped_avg_weight = df.groupby('Habitat')['Weight (kg)'].mean()
The function here groups all the animals by habitat and weight. It then takes the mean value of each habitat, providing you with a list of habitats and the average animal weight for each:
HabitatAntarctica 50.0Forest 100.0Grassland 232.5Jungle 190.0Savannah 2130.0Wetlands 3.0
Merging, joining, and concatenating DataFrames
In a real-world scenario, all the data you need won’t be constricted to just a single DataFrame. It’s actually a good practice to separate your data into different tables and use methods to join them when retrieving results. For example, a zoo might have several data tables – on top of the existing list, each animal could also have a separate table about their diet and conservation status:
Animal Diet Conservation Status0 Panda Herbivore Vulnerable1 Elephant Herbivore Endangered2 Giraffe Herbivore Vulnerable3 Lion Carnivore Vulnerable4 Zebra Herbivore Least Concern
You can grab the example CSV file here or create your own.
Import the file the same way as you did previously. Here’s the modified beginning of the code:
import pandas as pddf1 = pd.read_csv('zoo_animals.csv')df2 = pd.read_csv('animal_info.csv')
The main difference to note is that the df variables were numbered, and a second DataFrame was imported.
Merging DataFrames
Merging is a method to combine two DataFrames based on one or more keys (columns). If you’ve worked with SQL before, you’ll find these join methods very familiar (inner, outer, left, and right joins).
To merge rows, write the following code:
pd.merge(df1, df2, how='inner', on='Animal')
The above will use the inner join method and merge on the shared column 'Animal.' Here’s the full code to help visualize the process:
import pandas as pddf1 = pd.read_csv('zoo_animals.csv')df2 = pd.read_csv('animal_info.csv')new_table = pd.merge(df1, df2, how='inner', on='Animal')print(new_table)
Joining DataFrames
The join method is used to combine two DataFrames based on their indexes or a key column. It's a convenient method for merging with an index, which is useful when the DataFrames share the same index:
df1.join(df2, how='join_type', on='key_column')
Concatenating multiple DataFrames
Concatenation is used to append DataFrames either vertically (stacked rows) or horizontally (added columns). It's useful when you have DataFrames with the same structure or when you want to stack them. The syntax is as follows:
pd.concat([df1, df2], axis=0) # axis=0 for row-wise (vertical) concatenationpd.concat([df1, df2], axis=1) # axis=1 for column-wise (horizontal) concatenation
For more in-depth information, check the official documentation on how to merge, join, concatenate, and compare DataFrames.
Data visualization with Pandas
While presenting data in a terminal can make you look cool and feel like a hacker, it won’t hold the attention of our current age generation. The solution? Present it in a nice-looking visual!
Here’s the good and bad news. The bad news is that Pandas, on its own, doesn’t have any ways to visualize data. The good news is that it integrates wonderfully with libraries that can, such as Matplotlib.
To begin, make sure you have a plotting library installed:
pip install matplotlib
Then, include it in your code:
import pandas as pdimport matplotlib.pyplot as plt
You can plot data directly from a DataFrame using the .plot function. Different ways exist, so pick one that you find best suited for your data.
As an example, a bar plot is used to compare quantities of categorical data. The entire script looks like this:
import pandas as pdimport matplotlib.pyplot as pltdf= pd.read_csv('zoo_animals.csv')df.groupby('Habitat')['Weight (kg)'].mean().plot(kind='bar')plt.title('Average Weight by Habitat')plt.ylabel('Weight (kg)')plt.show()
Here’s the beautiful result:
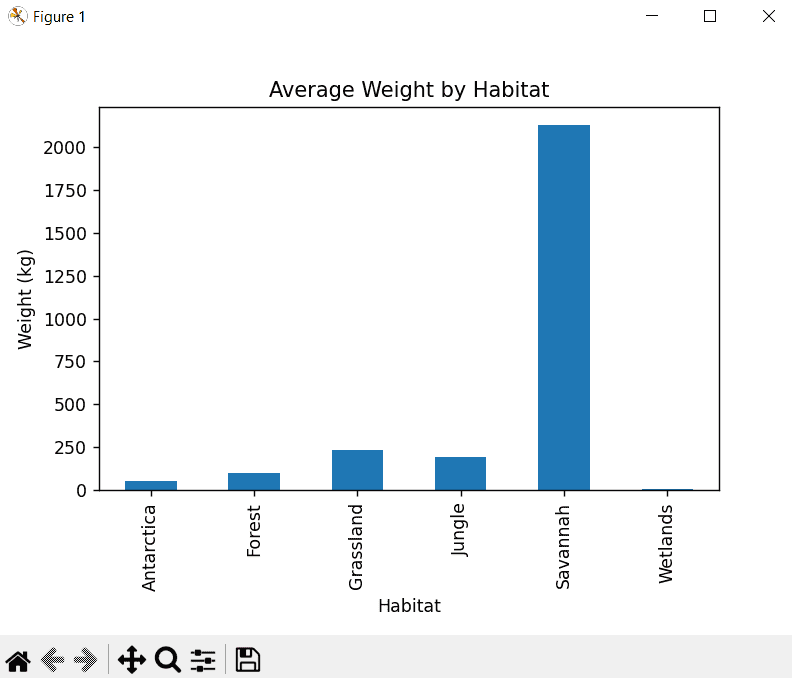
Use the buttons below the graph to pan and zoom into the data, as well as configure subplots or save the graph as an image file. It’s an incredibly fast way to visualize data with just a few lines of code!
You can even explore different types of graphs, as well as libraries that can help it visualize in more exciting ways. The best part is that Pandas is built to easily integrate with a lot of them, so the possibilities are endless.
Best practices and tips
When working with Pandas, following optimization techniques, best coding practices, and avoiding common pitfalls can greatly improve your code's performance and readability.
Optimizing performance with Pandas
Performance optimization is a top priority when working with large datasets in Pandas. One way to improve speed is using vectorized operations rather than iterating over rows, as Pandas is built for column-wise operations. Memory usage can be reduced by downcasting data types and filtering data early on using .query or boolean indexing to avoid unnecessary processing.
Writing clean and efficient Pandas code
Writing clean code increases readability and efficiency. Start by keeping your code modular by breaking complex chains of operations into smaller, reusable functions. It’s also important to use clear and descriptive column names so that developers who use your code don’t get lost. Documentation is also key – use comments and write comprehensive guides to explain how your code works (you’ll thank yourself later, too).
Common pitfalls to avoid
While Pandas may seem intuitive and simple to use, there are a few things worth keeping in mind that many might overlook:
- Using loops instead of vectorized operations. Iterating over DataFrame rows with loops is much slower compared to Pandas' built-in vectorized functions. Always prefer vectorized operations for faster performance.
- Neglecting missing data. Failing to check and handle NaN values before calculations can lead to unexpected results. Use methods like .fillna() or .dropna() to manage missing data appropriately.
- Chained indexing. Avoid using chained indexing, as it can lead to ambiguous behavior and performance issues. Instead, use .loc[] for reliable and efficient data selection.
Final words
Python Pandas remains one of the most intuitive libraries for data manipulation and analysis. Although it may have a steep learning curve, by progressing step by step, you'll soon be able to master it with confidence. Apply the methods covered in this article, experiment with them, and carry this knowledge forward in your data analytics journey. ?
About the author

Zilvinas Tamulis
Technical Copywriter
A technical writer with over 4 years of experience, Žilvinas blends his studies in Multimedia & Computer Design with practical expertise in creating user manuals, guides, and technical documentation. His work includes developing web projects used by hundreds daily, drawing from hands-on experience with JavaScript, PHP, and Python.
Connect with Žilvinas via LinkedIn
All information on Smartproxy Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may belinked therein.


