



Take Your Web Scraping To The Next Level – Scraping Dynamic Content With Python
The internet has changed quite a bit, hasn't it? Today, almost every popular website you go to is tailored to your specific needs. The goal is to make the user experience as good as possible. It sounds amazing for the end-user, but for someone who’s trying to data scrape dynamic content, it can prove to be quite the challenge. That doesn’t mean it’s not doable!
In this blog post, we’ll go through a step-by-step guide on how to web scrape dynamic content with Python and Selenium. While we’ll do our best to make this guide as clear as possible, this guide isn’t exactly a walk in the park. So if you’re new to web scraping, you might want to gain more scraping experience before tackling this quest.

What’s dynamic content?
More and more websites are investing time and money into researching their client base. This information is used to make a unique experience on a website for each user. It allows websites to make sure that their visitors get exactly what they need.
That’s essentially what dynamic content is. The content changes according to several factors such as demographics, language settings, time of day or season, location, etc. By employing this method, online business owners have an opportunity to engage with their clients, build interest and, in the best-case scenario, convert visitors into customers.
I mean, look at Google. By knowing the location, time, language, demographics, and even the behavior (debatable) of its users, Google provides the most relevant information. Granted, that can at first feel a little uneasy – we often don’t realize just how much information about us there is online. But in the end, we come to Google with a very specific need, and we want to get it ASAP.

Dynamic content vs. static content
There are two types of online content – dynamic and static. Let’s look over them and compare them briefly to get a clearer image.
- Dynamic content is unique to every person who visits a website. Not only that, but the more they return to the same dynamic website, the more it will change. Dynamic websites store information about you and adapt their content. This is also why dynamic websites are faster than static websites – because of the stored information.
- Static content can be observed in websites where, no matter who is the visitor, the content stays the same for everyone. So let’s say you encounter two websites on the same topic, but one is dynamic and the other – static. A dynamic website will try to tailor its’ content to what best matches a certain user; on the other hand, static content will remain the same for every user.
Benefits of dynamic websites
Improved professional image. Making sure that your website caters to each individual visitor helps boost trust and interest.
Shorter buyer’s journey. More often than not potential buyers leave a website because of the check-out process. It can either be too long or laggy. But with a dynamic website, the process becomes much easier since your information is stored.
Personalized user experience. Let’s be honest, it’s always nice to be appreciated and noticed. That’s exactly what you’ll get with a dynamic website.
Better website ranking. By researching your audience and catering to their needs you’ll definitely see a boost in your SEO metrics.
Faster loading time. Since dynamic websites store information about your visits, the loading time becomes much shorter as there’s no need to retrieve the same information.
Examples of dynamic content
Okay, so dynamic content is essentially displaying specific information to a user according to several factors we went over in the previous section. But where exactly can we find dynamic content? Let’s look at some examples.
- Landing pages.
- Emails and newsletters.
- Product pages.
- Ads on websites.
- Blog posts and articles.
- Website navigation.
- YouTube.
In all of the above-mentioned examples, the information that is displayed is unique to the user. Sure, the ultimate purpose of dynamic content is conversion, but it’s also important to generate interest and build a long-lasting relationship.
Challenges of web scraping dynamic content
As you’ve no doubt already gathered – otherwise, you wouldn’t have landed on this blog post – scraping dynamic websites can be vexing. However, with the right tech know-how, it can be done relatively easily. Here are some of the main challenges you might encounter:
- Finding the elements you need for the data you want to scrape. Dynamic content isn’t stored in HTML but rather server-based. It changes with every new visitor and visit, so getting everything regardless of that can be difficult.
- Making your scraper “catch” selected elements on every page you’ve selected. Dynamic content is fickle, so you can imagine how troublesome it can be to have a scraper catch all of the needed elements.
- Not very beginner-friendly. Web scraping dynamic websites requires both knowledge and experience.

Scraping time – what you’ll need to get started
Python is one of the most popular programming languages out there, and for good reason. Its versatility makes it easy to work with, and the extensive library of additional tools is definitely another plus for Python. That’s why we’ll also use it to web scrape dynamic content.
This guide was made using Windows, but the process is very much the same with Mac OS and Linux. Before we begin with this guide, let’s start with what we’ll need for this guide.
Smartproxy’s help documents
Our documentation is very detailed and almost literally covers it all. You’ll find loads of valuable information with great examples and explanations. Whether you find this guide helpful or not, having our help docs somewhere nearby will definitely not hurt.
Python
You probably already have Python, but if you want to get down to specifics, we used version 3.9.7. If by any chance you don’t have it, simply download it from https://www.python.org/downloads/.
Smartproxy’s residential proxies
To start using our residential proxies, first sign up to our dashboard. Once you’ve done that and verified your account, simply select a residential subscription plan that suits your needs best. Then you’ll need to choose an authentication method:
- Username:Password
- Whitelisted IP
Choose the second option and whitelist your IP. We’ll need to set up Selenium for headless scraping, which works only with IP whitelisting. In other cases, when you’re running a Selenium in headful mode, you can also choose the username:password authentication method (you can check how to do it on our GitHub.)
If there are any hiccups along the way, drop a line to our awesome round-the-clock customer support team. They’ll help you with any issues that may arise with your subscription.
Selenium
Selenium is a great automation tool that will help us in this guide. There are a few steps to follow in order to get it up and running, so here’s a link to our GitHub where everything is explained thoroughly and with screenshots included as well.
Don’t forget to choose the web driver of the browser you’ll be using. It will be important in the upcoming steps.
And it doesn’t stop there, we’ll also need other libraries – Pprint and By method. But I will show you how to add them later in the guide to make the process of scraping dynamic content as understandable as we can.
Target website
It can literally be almost anything you want, but for this guide, we’ll be using http://quotes.toscrape.com/. From this dynamic website, we will scrape quotes, tags, and authors.
Scraping dynamic content with Python and Selenium: a step-by-step guide
Step 1: Viewing the page source
Let’s get this show on the road! Go to our target website and inspect the HTML.
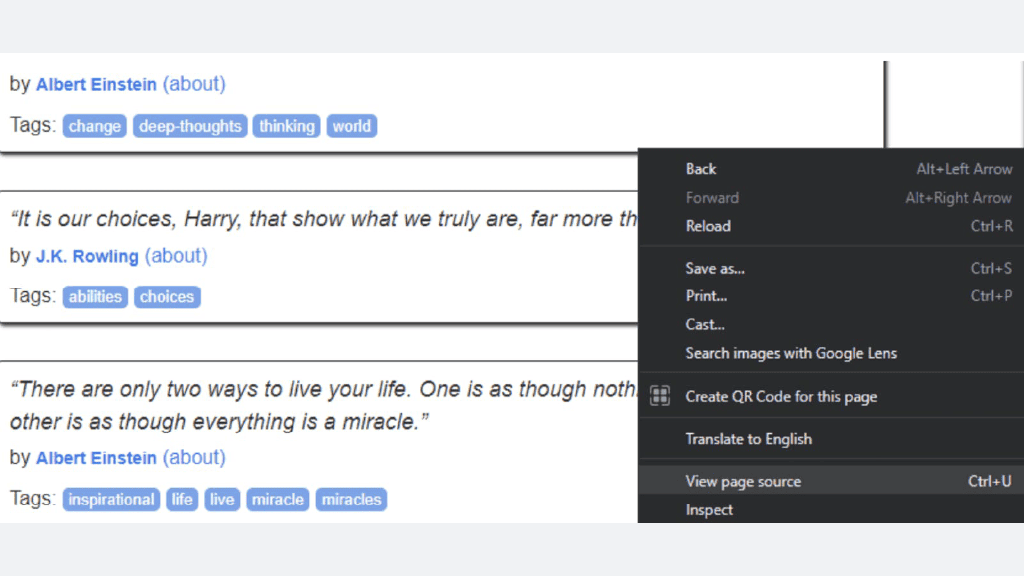
Step 2: Choosing elements
Now that you have the HTML opened up in front of you, you’ll need to find the correct elements. Since the website we chose contains quotes from famous authors, we are going to scrape the elements with the following classes:
- ‘quote’ (the whole quote entry)
- ‘Text’
- ‘author’
- ‘tag’
And then for each of the quotes, we’ll select these classes:
<div class="quote" itemscope itemtype="http://schema.org/CreativeWork"><span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."</span><span>by <small class="author" itemprop="author">Albert Einstein</small><a href="/author/Albert-Einstein">(about)</a></span><div class="tags">Tags:<meta class="keywords" itemprop="keywords" content="change, deep-thoughts, thinking, world" / ><a class="tag" href="/tag/change/page/1/">change</a><a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a><a class="tag" href="/tag/thinking/page/1/">thinking</a><a class="tag" href="/tag/world/page/1/">world</a></div></div>
Step 3: Adding the By method and pprint
We already have Selenium set up, but we also need to add the By method from the Selenium Python library to simplify selection. Basically, this method lets you know whether or not certain elements are present.
from selenium import webdriverfrom selenium_python import get_driver_settings, smartproxy# using By to simplify selectionfrom selenium.webdriver.common.by import By
We’re also gonna need pprint – it’ll format the results in a neat way. You can add it by typing in the code line as in the example down below
#pprint to make console output look niceimport pprint
Step 4: Choosing a browser and specifying the target
You can totally leave the driver setup like it is in the example, just make sure to add choose the browser you’ll be scraping. As for the target (http://quotes.toscrape.com), it should be typed in exactly as in the example.
def webdriver_example():driver get_driver_settings()if driver['DRIVER'] == 'FIREFOX':browser =webdriver.Firefox(executable_path=r'{driver_path}'.format(driver_path=driver('DRIVER_PATH']), proxy=smartproxy())elif driver ['DRIVER'] == 'CHROME':browser =webdriver.Chrome(executable_path=r'{driver_path}'.format(driver_path=driver('DRIVER_PATH']), desired_capabilities=smartproxy())browser.get('http://quotes.toscrape.com/')
Now let’s also set up a variable of how many pages we will want to scrape. Let’s say we’ll want 5. The scraper output is going to be a list of JSON objects quotes_list containing information about the quotes we’ll scrape.
browser.get('http://quotes.toscrape.com/')pages = 5quotes_list = []
Step 5: Choosing a selector
You can choose from a variety of selectors, but for this guide we used Class. Let’s go back to the Selenium Python library for a bit. We’re going to locate our elements by using the Class selector in this case ( By.CLASS_NAME ).
Now that we have our selector up and running, the first thing that we have to do is open the target website in Selenium. The command line will do just that. It’s time to get the information that we need.
browser.get('http://quotes.toscrape.com/')
Step 6: Scraping
It’s finally time to start doing some scraping. Don’t worry, yes, there will be quite a bit of code to tackle, but we’ll give examples and explain each step of the process. This way we’ll break it down into smaller, easier-to-understand bits and you’ll be cracking dynamic content in no time.
for i in range (pages) :quotes = browser.find_elements(By.CLASS_NAME, 'quote')for quote in quotes:tags = quote.find_elements(By.CLASS_NAME, 'tag'),tag_list = []for tag_in tags:tag_list.append(tag.text)quotes_list.append({"author' : quote.find_element(By.CLASS_NAME, 'author').text,'text' : quote.find_element(By.CLASS_NAME, 'text').text,'tags' : tag_list,})next_page_btn = browser.find_element(By.PARTIAL_LINK_TEXT, 'Next').click()
for i in range(pages):
The loop is going to run as many times as we have selected in the pages variable. We went for 5 pages.
quotes = browser.find_elements(By.CLASS_NAME, ‘quote’)
With this line, we will get all of the ‘quote’ class elements from the page. As in the example below:
<div class="quote" itemscope itemtype="http://schema.org/CreativeWork"><span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."</span><span>by <small class="author" itemprop="author">Albert Einstein</small><a href="/author/Albert-Einstein">(about)</a></span><div class="tags">Tags:<meta class="keywords" itemprop="keywords" content="change, deep-thoughts, thinking, world" / ><a class="tag" href="/tag/change/page/1/">change</a><a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a><a class="tag" href="/tag/thinking/page/1/">thinking</a><a class="tag" href="/tag/world/page/1/">world</a></div></div>
for quote in quotes:
The above code line goes through all of the quote elements repeatedly.
tags = quote.find_elements(By.CLASS_NAME, 'tag')tag_list = []for tag in tags:tag_list.append(tag.text)
By selecting the tag class we will get all of the tags for a given quote. Then we will iterate through them to put them in a list – tag_list.
quotes_list.append({
Adds the output to the quotes_list list that was mentioned earlier. The list will contain JSON elements for each quote.
'author' : quote.find_element(By.CLASS_NAME, 'author').text,'text' : quote.find_element(By.CLASS_NAME, 'text').text,
Here we’re selecting the quote text itself as well as the author. There can only be one of each so there’s no need to iterate. The values are assigned to the ‘author’ and ‘text’ keys respectively.
'tags' : tag_list,
Assigning the tag_list to the ‘tags’ key.
next_page_btn = browser.find_element(By.PARTIAL_LINK_TEXT, 'Next ').click()
We’re finding the next page button (using the PARTIAL_LINK_TEXT selector) and clicking on it to go to the next page. A new loop iteration starts after that and the page is scraped for quotes again.
<nav><ul class="pager"><li class="next"><a href="/page/2/">Next <span aria-hidden="true">→</span></a></li></ul></nav>
Step 7: Formatting the results
We’re nearing the finish line. All that’s left now is to add the last line of code that will print out the results of your scraping request to the console window after the pages finish scraping.
pprint.pprint (quotes_list)
…and we’re done! After this, you should see something similar to the example below. Now, mind you, the results are quite a bit more extensive than shown here, but, well, you get the point.
[{'author': 'Albert Einstein','tags': ['change', 'deep-thoughts', 'thinking', 'world'],'text': '"The world as we have created it is a process of our thinking. It''cannot be changed without changing our thinking."'},{'author': 'J.K. Rowling','tags': ['abilities', 'choices'],'text': '"It is our choices, Harry, that show what we truly are, far more''than our abilities."'},'{'author': 'Albert Einstein','tags': ['inspirational', 'life', 'live', 'miracle', 'miracles'],'text': "There are only two ways to live your life. One is as though''nothing is a miracle. The other is as though everything is a''miracle."'},
Conclusion
Web scraping is becoming more and more popular these days. There’s just so much knowledge you can gain with this data collection method. Not to mention the numerous ways you can use this information to your advantage. We chose a rather simple website to scrape, so it can require more work to scrape a more sophisticated website. But at least now you have a good example of how to work with dynamic websites!
About the author

James Keenan
Senior content writer
The automation and anonymity evangelist at Smartproxy. He believes in data freedom and everyone’s right to become a self-starter. James is here to share knowledge and help you succeed with residential proxies.
All information on Smartproxy Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may belinked therein.

