How to Scrape Google Search Data
Business success is driven by data, and few data sources are as valuable as Google’s Search Engine Results Page (SERP). Collecting this data can be complex, but various tools and automation techniques make it easier. This guide explores practical ways to scrape Google search results, highlights the benefits of such efforts, and addresses common challenges.
What is Google SERP?
A Google Search Engine Results Page (SERP) is the page you see after entering a query, such as "egg boiling time," into Google's search bar. Originally just a list of links, today’s SERPs include rich snippets – like Knowledge Graphs, People Also Ask boxes, reviews, and news – that make the results more dynamic and informative. Because of the wealth of data they contain, scraping Google search results is a popular way for businesses to gain valuable insights into SEO, competitive analysis, and market research.
Elements of a Google SERP that can be scraped
Before you start scraping, it’s important to understand that Google’s SERPs have evolved beyond simple lists of links to include a range of visually rich and interactive features. Searching for a relevant keyword reveals various data points that can be extracted using scraping tools like our SERP Scraping API.
- Paid and organic search results
- Ads
- Videos
- Images
- Popular products (Shopping listings)
- Related questions (People Also Ask)
- Related searches
- Featured snippets
- Local pack (including restaurant listings and other local businesses)
- Top stories (news)
- Recipes
- Jobs
- Knowledge panels
- Travel results (hotels, flights)
If you're interested in identifying the SERP features associated with your selected keywords, the SE Ranking rank tracker is a useful tool that allows monitoring more than 35 different SERP features.
Why scrape Google search results
Google captures roughly 82% of the global search market, far surpassing competitors like Bing at around 11%, so it's likely that both your customers and competitors appear in Google’s vast ecosystem.
For businesses, Google’s search results offer far more than just a list of webpages. By examining the queries people enter, the ads they respond to, and the links they click, companies can gain a detailed understanding of consumer needs and preferences. Scraping this data allows to:
- Identify trending topics and emerging customer demands before they become widespread, enabling early product development or strategic pivots.
- Monitor competitor activity to stay one step ahead in the market, including new product launches, special promotions, and shifts in messaging.
- Discover gaps in existing offerings, highlighting opportunities to create new products, services, or content that answer unmet consumer needs.
- Assess user sentiment and brand perception by analyzing how and where a company’s name or products appear, as well as what related questions people ask.
- Refine SEO and advertising strategies by understanding which search terms attract the most attention, and how well certain keywords convert into traffic or sales.
In short, scraping Google’s SERPs can yield invaluable insights into consumer behavior, market direction, and competitive landscapes – powerful information that helps businesses make data-driven decisions, innovate effectively, and maintain a competitive edge.
Ways to scrape Google search results
Unfortunately, Google doesn't provide an official method for accessing search data at scale, so without a dedicated API, collecting this information becomes a challenge.
While you can try manual collection, it’s both time-consuming and prone to inaccuracies. Instead, most businesses opt for one of three methods: semi-automation, full automation managed in-house, or leveraging professional tools that streamline the process – such as those offered by Smartproxy.
1. Semi-automated data gathering
Building a custom scraper from scratch requires coding expertise and technical effort, but depending on your needs, a semi-automated approach may suffice. For instance, you can create a basic scraper in Google Sheets without writing any code and simply using a few specialized formulas. This approach works well for extracting basic information (e.g., meta titles, meta descriptions, authors) from a small set of pages competing for the same keyword on Google.
By employing a custom version of the IMPORTXML function with an XPath query, you can pull specific elements directly from a page’s HTML. While this method can be effective for simple, small-scale tasks, it does involve some manual setup and cannot efficiently handle large volumes of data.
2. Automated data gathering by building your own scraper
For larger-scale or more complex data needs, building your own web scraper can be a powerful solution. A custom scraper, which you can program to visit thousands of pages, will extract and store data automatically. By feeding it a Google Search query, it can continuously crawl and gather the information you require.
However, website owners (including Google) actively discourage automated data extraction. Anti-bot measures may ban your IP address if they suspect non-human activity. To avoid this, proxies are essential. They rotate your IP address, helping the scraper appear as a genuine visitor. Smartproxy provides high-quality residential, mobile, static residential (ISP), and datacenter IPs designed for scraping tasks, delivering fast response times, high success rates, and impeccable uptime.
While building your own scraper offers flexibility and customization, it also presents technical challenges. You’ll need to handle user-agent testing, rate limiting, human-like behavior, IP blocklisting, CAPTCHAs, and other possible hurdles.
3. Automated data gathering using Smartproxy's SERP Scraping API
If building and maintaining your own scraper doesn't sound appealing, consider using our SERP Scraping API. It's a powerful tool that features 65M+ proxies, integrated browser fingerprinting, flexible output options, real-time or on-demand results, task scheduling, ready-made scraping templates, and more. It can streamline data extraction without requiring extensive technical know-how.
Many SEO professionals rely on these tools to conduct keyword research, track rankings, analyze backlinks, or extract structured data from Google Shopping, Images, or Hotels. With our Google Search API, you can efficiently gather the data needed to reach top positions in Google’s SERPs.
How to scrape using Smartproxy's SERP Scraping API
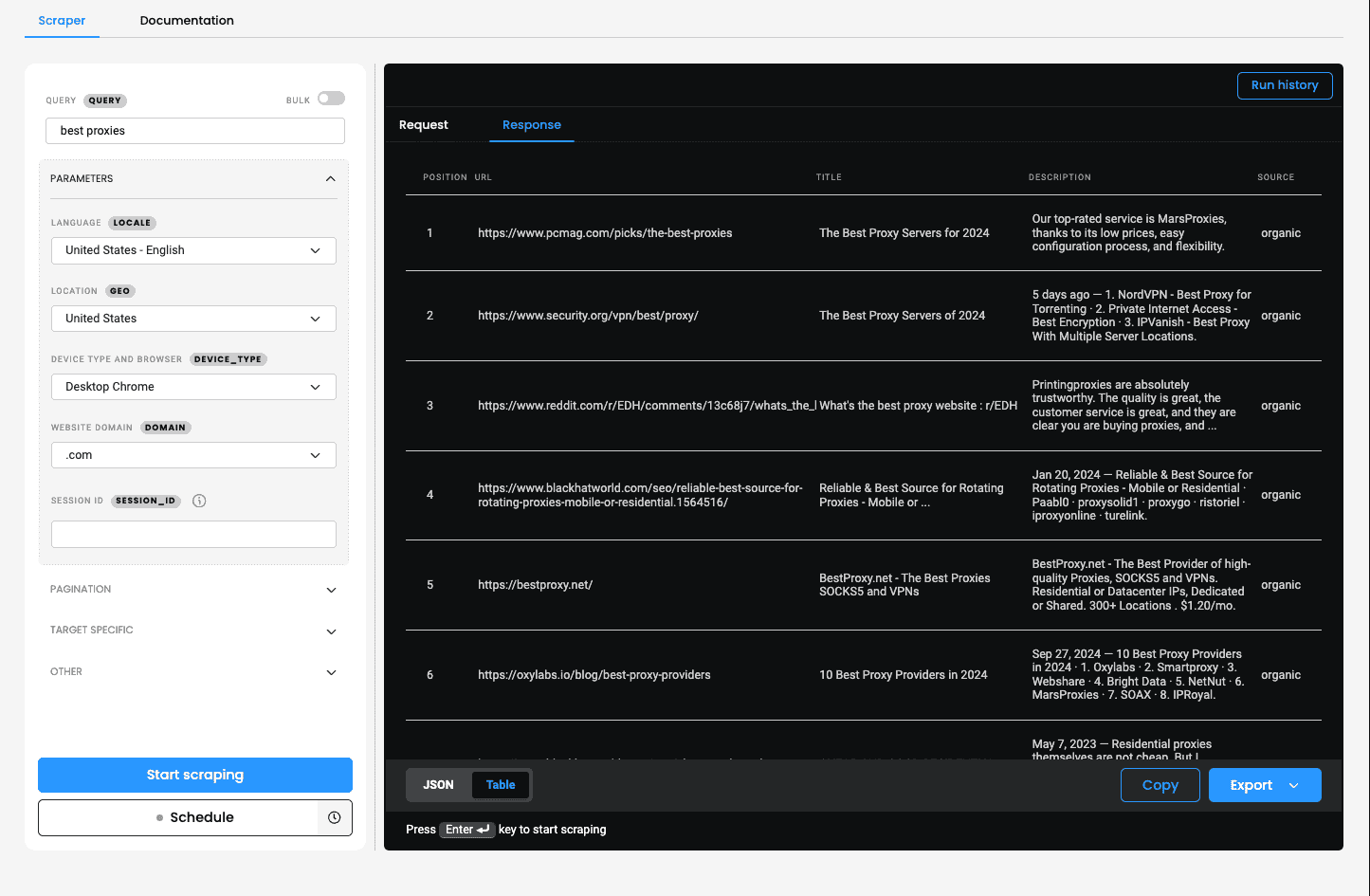
Let's explore how easy it is to scrape Google's search engine results pages using our SERP Scraping API. We'll search for the phrase "best proxies" and examine the top positions on the first page.
1. Get SERP Scraping API
First off, create an account or log in to your Smartproxy dashboard.
On the left panel, click Scraping APIs, select Pricing, and choose the SERP target group and a plan that suits your needs or claim a 7-day free trial to test our service.
2. Configure a scraping request
Next, in the Scrapers section, you can click Create new scraper or choose one from the Popular Scrapers below.
Since we want to scrape Google's search results, let's use the Google Search scraper. This action will take you to the scraper view where you can enter "best proxies" as the query and configure various parameters like language, location, device type, browser, website domain, pagination, target specific settings, and more.
Once you've set your configurations, you can see the code sample on the window on the right be adjusted. You can copy this code in cURL, Node.js, and Python and integrate it in your development environment.
Here's an example of the code in Python:
import requestsurl = "https://scraper-api.smartproxy.com/v2/scrape"payload = {"target": "google_search","query": "best proxies","locale": "en-us","geo": "United States","device_type": "desktop_chrome","domain": "com","page_from": "1","num_pages": "10","google_results_language": "en","parse": True}headers = {"accept": "application/json","content-type": "application/json","authorization": "Basic [BASE64_ENCODED_CREDENTIALS]"}response = requests.post(url, json=payload, headers=headers)print(response.text)
3. Send a request
Instead of copying and using the code elsewhere, you can perform scraping tasks right here in your browser. Simply click Save & Scrape and receive the response shortly in JSON and table format.
Meanwhile, clicking the Schedule button executes your project and delivers the response to your email address, webhook, or Google Drive at intervals that suit you – hourly, daily, weekly, monthly, or a custom rate.
4. Export the result
With this specific Google Search scraping template, you can scrape positions, URLs, titles, descriptions, source types, and more. Click the Export button to download the response in JSON or CSV.
Scraping methods summarized
Now that you have a better idea about how to gather Google search data, let’s quickly recap your possibilities.
Pros
Cons
Semi-automated
- Free
- Easy to set up
- No risk of getting your IP blacklisted
- Manual-heavy; needs a lot of input
- Limited automation and data scope
DIY scraper
- Free to build
- Highly customizable
- Can be as detailed as you like
- Time- and labor-intensive
- Requires coding knowledge
- Must keep up with Google’s anti-scraping measures
- Requires proxy integration
Third-party tools
- No technical knowledge required
- Easy to use
- Powerful, fast, and nearly limitless data gathering
- Paid solution
- Limited by the tool’s capabilities
Closing thoughts
The best solution for scraping data from Google depends on your business needs, expertise, and budget. Building your own scraper can be flexible and cost-effective if you’re comfortable with coding and have the time. Otherwise, using our SERP Scraping API is a better option – it saves programming time and effort while effortlessly gathering various data points. Try our Google Search Scraping API today with a 14-day money-back option or a 7-day free trial for first-time users!
About the author

Dominykas Niaura
Technical Copywriter
Dominykas brings a unique blend of philosophical insight and technical expertise to his writing. Starting his career as a film critic and music industry copywriter, he's now an expert in making complex proxy and web scraping concepts accessible to everyone.
Connect with Dominykas via LinkedIn
All information on Smartproxy Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may belinked therein.