



How to Collect Big Data?
It probably wouldn't be too bold to state that data-driven decisions rule the world. Gathering big data can open up crucial insights to improve your business strategy and activities.
A massive amount of data is out there, and its growth is nowhere near the finish line. It's expected there will be 63 zettabytes of data floating on the internet by 2025. We’re talking about 21 zeros here – an unfathomable amount of data.
The good news is that this enormous load of data could be handy for many businesses, big and small alike. If you are eager to open this Pandora's box, we will provide some valuable tips on how you can arrange that.

What is big data?
Big data can be described as super large datasets. Big data is used to spot patterns, problems, or other insights, benefiting decision-making.
Such enormous databases usually share "3V" as common features:
- Volume. Quite obvious from the title, but big data differences from regular databases are high volumes of information. It can be tens of terabytes of raw data, so volume is one of the key factors differentiating big data.
- Velocity. Big data comes along with the fast speed at which it can be received. In the best-case scenario, big data is collected and analyzed in real-time.
- Variety. Such large datasets don't have any fixed format. Big data rather stands for various types of informational units, traditional and alternative data types included. It doesn't matter if it's structured or unstructured datasets; if it's in audio, text, or video format – it counts as big data. If data comes in a non-textual form, it usually requires different processing.
Two extra Vs have been gaining more popularity recently – value and veracity. It can be regarded as big data if you can put all the check marks on those points.
Types of big data
Data could be produced in two different ways – it could be human-generated or device-produced. Device-driven datasets are often neat, while human-generated information usually is shared in different formats, and it could be messy to gather it in bulk.
Big data is usually divided into three categories depending on its structure. The analysis of contrasting types of data is different, therefore it is vital to understand what kind of data you have to deal with.
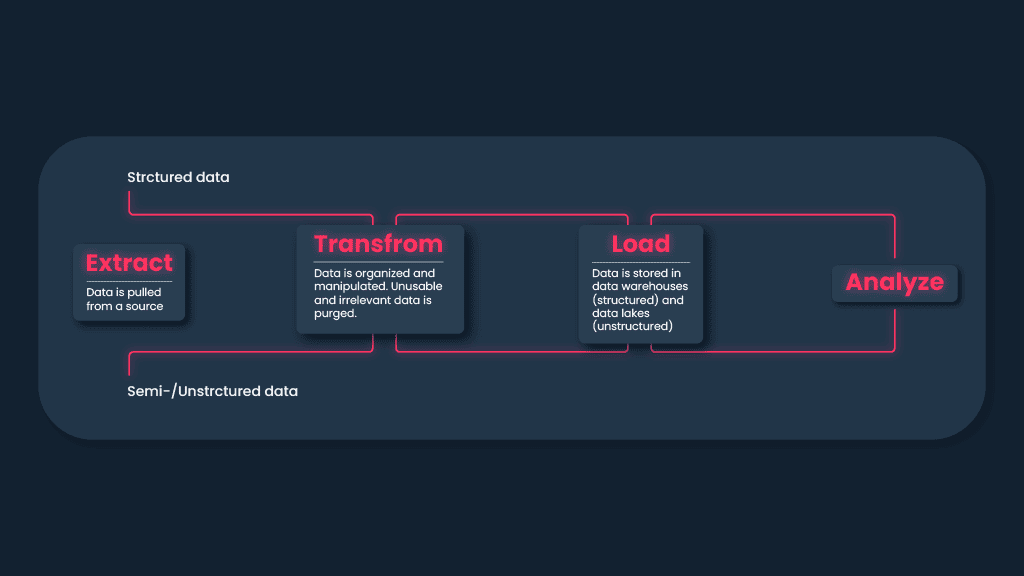
#1 Structured data
This type is the easiest to work with. It's organized according to preset parameters, applicable to all the units in the database. For example, the data presented in the rows and columns in a spreadsheet usually belongs to the structured type. Since the structured datasets have more tangible value, it's easier to program your scraper to collect it according to certain criteria.
Structuring large amounts of raw data can be quite an issue, therefore if you take data analysis seriously, you should think about a parser. You can purchase a ready-made parser or build it on your own – both options include some pros and cons. Read our guide on how to choose the best parser.
#2 Unstructured data
It's the kind of data that has nothing close to neatness or tidiness in its structure. It usually takes some time to unlock the hidden grail of unstructured datasets and make them suitable for analysis.
To make it readable, you must turn unstructured data into a structured format. The translation process isn't easy and can vary depending on each format. By the way, context is not in the last place while organizing such data – the more context is provided during the process, the more accurate the end result of data transformation will be.
#3 Semi-structured data
There should always be something in the middle, right? It is usually unstructured data paired with metadata details. For example, if you upload a picture, the publishing time becomes additional metainformation attached with the posted image. And it could be not only time but location, contact or device information, and IP address.
So, in a semi-structured data case, the core content is unstructured, but its components allow to group content units according to some characteristics. The analysis of semi-structured data usually follows the same processes as that of unstructured databases, however, it could be easier to filter and group the collected raw data in case it’s semi-structured. Because vast amounts of data must be stored, processed, and utilized for predictive techniques, there is not much time left for other services. Therefore, try to employ managed services providers as much as you can.
Benefits of big data collection
#1 Improve your customer experience
Since we live in customer-centric times, companies try to win new users by improving the added value of their offers. However, the customers' and providers' views of what's valuable can differ, so it's beneficial to know what your customers think.
Since it's impossible to read the minds of your customers, you have to go where they go and collect their thoughts or activities. Yep, we are talking about social media, their activity on your web, interaction with your dmarc secured emails, incoming calls' information, etc. Such data analysis is a way to understand their habits and trigger points better. Having great insights about your customers, you can fill the room for your product's improvements.
Finally, it can improve your operational efficiency as well. It may not make the headlines, but it is an essential part that affects your overall product quality.
#2 Prevent potential fraud
Cybersecurity can be a harsh subject since there's never enough actions taken to prevent fraud. Security landscape is dynamic and continually developing. Analyzing the gathered aggregate volume of data could aid you in identifying some patterns indicating fraudulent activities and make the reporting process smoother. By monitoring your customers' activities and credit card transactions, you can detect suspicious actions.
#3 Level up machine learning
More and more businesses invest in machine learning to improve the overall automation process while saving employees from mundane tasks. But for the devices to learn, there should be a great deal of data gathered in advance. Big data can be your answer here to make it happen.
Big data collection
One tool for data gathering
Proxies paired with a scraper can help you gather a vast sea of information and automate the whole data collection process like no one’s business. Web scraping can be tricky because if you overuse one IP address, the targeted websites and browsers can detect that your actions are “too heavy” or “too fast” to resemble real human actions. Pairing scrapers with proxies can help you bypass such restrictions. You can use proxies with your own scraper or, if you need data from search engines, simply take our SERP Scraping API. It guarantees a 100% request success rate and you won’t need to bother with proxies’ and scraper’s integration since it’s a full-stack solution.
Proxies for data harvesting
An elite proxy pool could be a great choice if you're looking for ways to upgrade your scraping. With it, you'll be able to bypass IP address blocks, hide your original one, and pick a location from which you want to make a request.
If you're choosing between residential and datacenter proxies, there are some things to keep in mind. Residential proxies are coming from the household devices, therefore their session could be less stable. On the other hand, they can mimic human behavior better, so residential IPs could be a good choice if you're sending many requests to a specific website with delicate sensors for bots.
Datacenter proxies are faster, cheaper, and more stable but if one IP gets compromised, it can affect other proxies too, since they share the same subnet. On the other hand, if you're collecting data from e-commerce websites with less sensitive anti-bot systems, datacenter IPs are a reasonable choice.
Proxy rotation is another thing you should consider before choosing your favorite ones. Rotating proxies allow you to change IP addresses with every request or choose sticky sessions of various lengths.
Wrapping up
Big data can seem tricky at first, but its collection is an important factor for better-informed business decisions. The trickiest part is to decide on the purpose of collection and what kind of data needs to be gathered.
If those questions are answered, it's time to pick tools to run all this process. We definitely have something to offer for you, so if you're hesitating, just fill out the form, and we will help you to choose among proxies and scraping solutions.
About the author

Mariam Nakani
Say hello to Mariam! She is very tech savvy - and wants you to be too. She has a lot of intel on residential proxy providers, and uses this knowledge to help you have a clear view of what is really worth your attention.
All information on Smartproxy Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may belinked therein.



