



Proxy APIs vs. Traditional Scraping: Choosing the Right Approach for Your Project
There’s no denying that today web scraping helps many businesses move toward informed and profitable decisions. From machine learning to market analysis, automatic publicly available data collection is a way to gather large amounts of valuable information.
Yet, modern websites are a challenging target – over the years, they have greatly improved their security measures, making it very difficult to scrape with regular extraction tools. So, businesses now face a dilemma: invest in a web scraping specialist or buy a service that takes care of aspects like CAPTCHAs, data parsing, and proxy management.

Challenges in traditional web scraping
Getting information from a web page with traditional web scraping tools like Python's Requests and Beautiful Soup was pretty simple: choose a target URL, send a request to download the HTML code, and extract the data points you want. Lastly, adjust the scraper as needed. Sounds easy enough?
It was until web owners started applying rigorous anti-bot systems. According to the yearly Bad Bot research by Imperva (2023), up to 30% of web traffic comes from malicious bots. Consequently, it is now a critical task for websites to protect data from unauthorized visitors. However, anti-bot measures disrupt the web scraping process; it has become difficult to handle traditional scripts, requiring more knowledge and resources when collecting public information.
Main protection methods that hinder the project's success
Here are a few examples of the main protection methods used by websites.
Rate limiting is a popular technique to control traffic flow to the website. A website owner chooses an identifier, such as an IP address to monitor its visitors. When you connect to a page without using a proxy or a VPN, the site can then track your real IP and location as well as restrict the number of requests you send to the server within a certain time frame. This could vary from 10 requests per second to 100 per minute.
Browser fingerprinting methods are able to track dozens of hardware and software parameters that need to be taken care of while web scraping. For example, if you’re using an HTTP client like Requests or Axios, you’ll need to emulate headers such as the user agent to spoof your identity. This requires constant adjustment and maintenance to avoid detection and blocking by websites.
CAPTCHAs are probably the most popular method used across different platforms. Various tasks based on passive and behavioral analyses are often too complicated for bots to handle. In this case, if you’re writing the code yourself, you’ll need to use a CAPTCHA-solving service, which can be slow and expensive, or avoid the challenge altogether, which requires web scraping expertise.

And these are just a few examples of anti-scraping techniques; you can also expect honeypots and other measures that might hinder your web scraping efforts.
A novel approach to data gathering – proxy APIs
When addressing the need to simplify the web scraping process, proxies and web scraping infrastructure providers added proxy APIs to their lineup. They aimed to cover aspects such as CAPTCHA handling, IP cooling, and browser fingerprinting. So, it’s become possible to extract data with almost a 100% success rate, even without being at the forefront of web scraping’s cat-and-mouse game.
A primer on proxy APIs
A proxy API, also known as a web (site) unblocker or simply a web scraping API, integrates as a proxy server. But the tool combines multiple proxy types and website unblocking mechanisms in the backend.
In essence, the primary purpose of a proxy API service is to provide uninterrupted access to any target – no matter the protection mechanism it uses. To better grasp the functionality, if a request fails by encountering CAPTCHAs or any other roadblocks, a proxy API adjusts the configuration as needed and retries until it succeeds.

What’s more, a proxy API comes with the features of a regular proxy server. You can establish sessions, and choose precise location settings that can reach co-ordinate and ISP level.
The process of using a web unblocker includes a hostname and port with authentication details. Then, you can add different parameters like location to the credentials or send them as a custom header. At the end, the API adjusts its configuration and fetches your results.
curl -k -v -x unblock.smartproxy.com:60000 -U "USERNAME:PASSWORD" "https://ip.smartproxy.com/"
Advantages of Using a Proxy API for Web Scraping
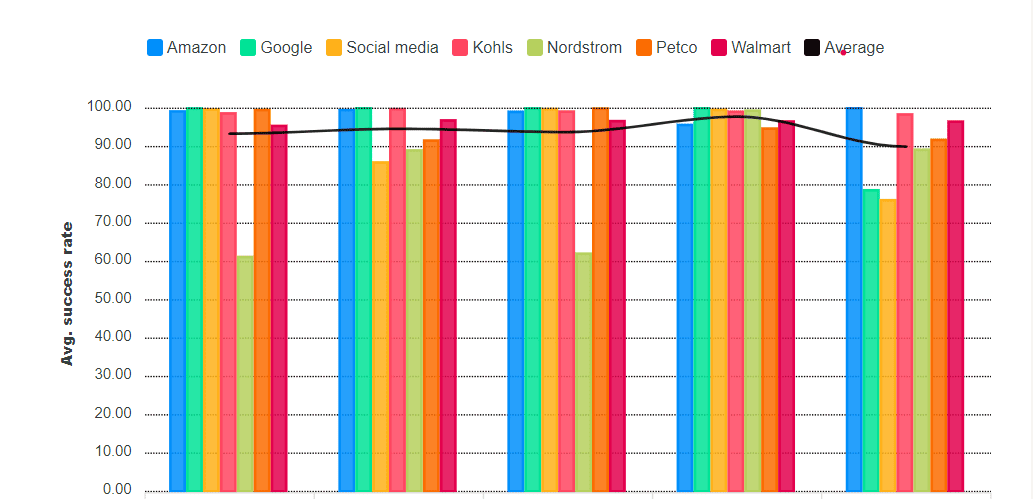
Very high success rate. According to Proxyway’s research on five major web scraping companies that offer proxy APIs, the success rate with challenging websites was above 90%. The investigation covered seven targets, like Nordstrom, protected by various anti-bot systems.
Average success rate of major companies.
Automatic proxy management. Proxies can be vital for a web scraping project's success. However, each task requires a different type of server. For example, residential IP addresses might be an overkill with unprotected websites. In this case, you could cut the budget with datacenter proxies. A proxy API automatically selects the appropriate type.
Browser fingerprint spoofing. Proxy APIs also handle the browser fingerprints – they automatically select the right request headers, passive fingerprints, and other relevant data points. As a result, you don't have to write or keep up with the unblocking logic on your own.
Request and CAPTCHAs management. A proxy API can deal with CAPTCHAs. It achieves that by avoiding the challenge altogether rather than forcing it through. Pages that always show CAPTCHAs pop-ups might still require your input. Additionally, if the request fails, a proxy API retries it until it succeeds.
JavaScript rendering. Most APIs can render JavaScript without the need for additional tools. This removes the need to run your own headless browser instances, saving time and potentially money if you haven’t optimized the process. Additionally, some APIs like Smartproxy’s Site Unblocker allow you to receive a screenshot instead of the HTML source.
Simple to integrate. Using a proxy API is similar to proxies – you have a single endpoint in hostname:port, which you can add to your code in place of a regular proxy server.
Things to consider before buying a proxy API
Even though proxy APIs can handle JavaScript, their main drawback is that they're inflexible towards dynamic content – most tools don't expose the parameters needed to interact with the page. So, a proxy API isn't the best option for content that requires user interaction.
Very few providers in the market offer proxy APIs that support integration with headless browser libraries like Puppeteer or Playwright. By design, proxy APIs are incompatible with third-party tools.
What’s more, proxy API services can get pricey, especially when it comes to JavaScript rendering. Some providers charge extra when you enable the feature, and the cost can become an order of magnitude more expensive.
If you're looking for a flexible solution, check out Smartproxy's residential proxy API, which enables seamless proxy management.
The bottom line
Using traditional web scraping tools has its own benefits, but at the same time, it requires a lot of knowledge and resources to maintain the script. Proxy APIs, on the other hand, take some load off the user – they handle technical challenges like CAPTCHAs management when unblocking popular targets with strong anti-bot systems.
If you'd like to learn more, check out our guide on the best proxy service providers. We've also reviewed the top residential proxy services and anti-detect browsers on the market, so we invite you to take a look!
The information provided here is valid as of 13-02-2024. Please be advised that circumstances and facts may change over time, rendering this information outdated or incomplete. Performance data is taken from Proxyway Market Research 2023.