



Scraping Amazon with ParseHub
No need for knowing how to code, no need for writing your own scripts.
For this beginner tutorial, we’ll be scraping the following details of comedy movie Blue-rays: number of reviews, price and the names of directors.
14-day money-back option

If you want to make web scraping easy, you can’t go wrong with using ParseHub. It’s not only perfect for absolute beginners, it’s also the best choice for those who need things done fast and easy.
Quick note: as layouts of various Amazon pages might differ, the selection process might be a bit different as well.
Getting Started
Before we get into action, let’s get two things covered. First, make sure you’re using reliable scraping proxies as they can definitely make or break your project. What happens if you don’t use proxies? You get clocked, your IP blocked and you can wave your research goodbye.
The second one, money business. As a software, ParseHub is available to anyone and has quite a good free plan. It allows you to scrape 200 pages in 40 minutes and create 5 custom projects. If that’s not enough, you can check out their paid plans, starting at $149 per month.
So let’s dive in. Hopefully you’ve registered and downloaded the software at this point (if not, c’mon, do it now and let’s see how it works together).
Scraping Product Lists
Once you open ParseHub, click on Create New Project, put in the URL of the page you want to scrape. In this case, we’ll be scraping comedy movie details on Amazon.
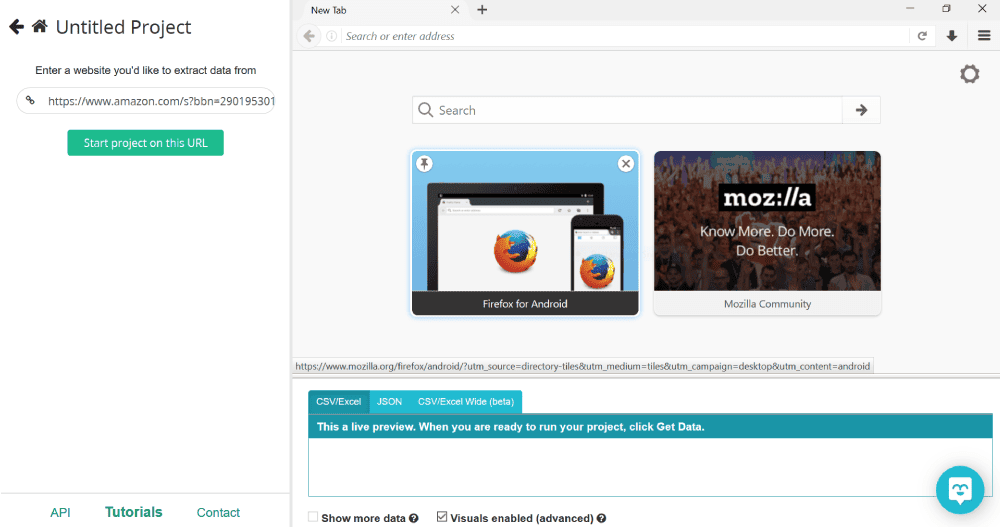
Clicking on Start project on this URL will open the window in the integrated browser in ParseHub itself which is a very convenient feature.
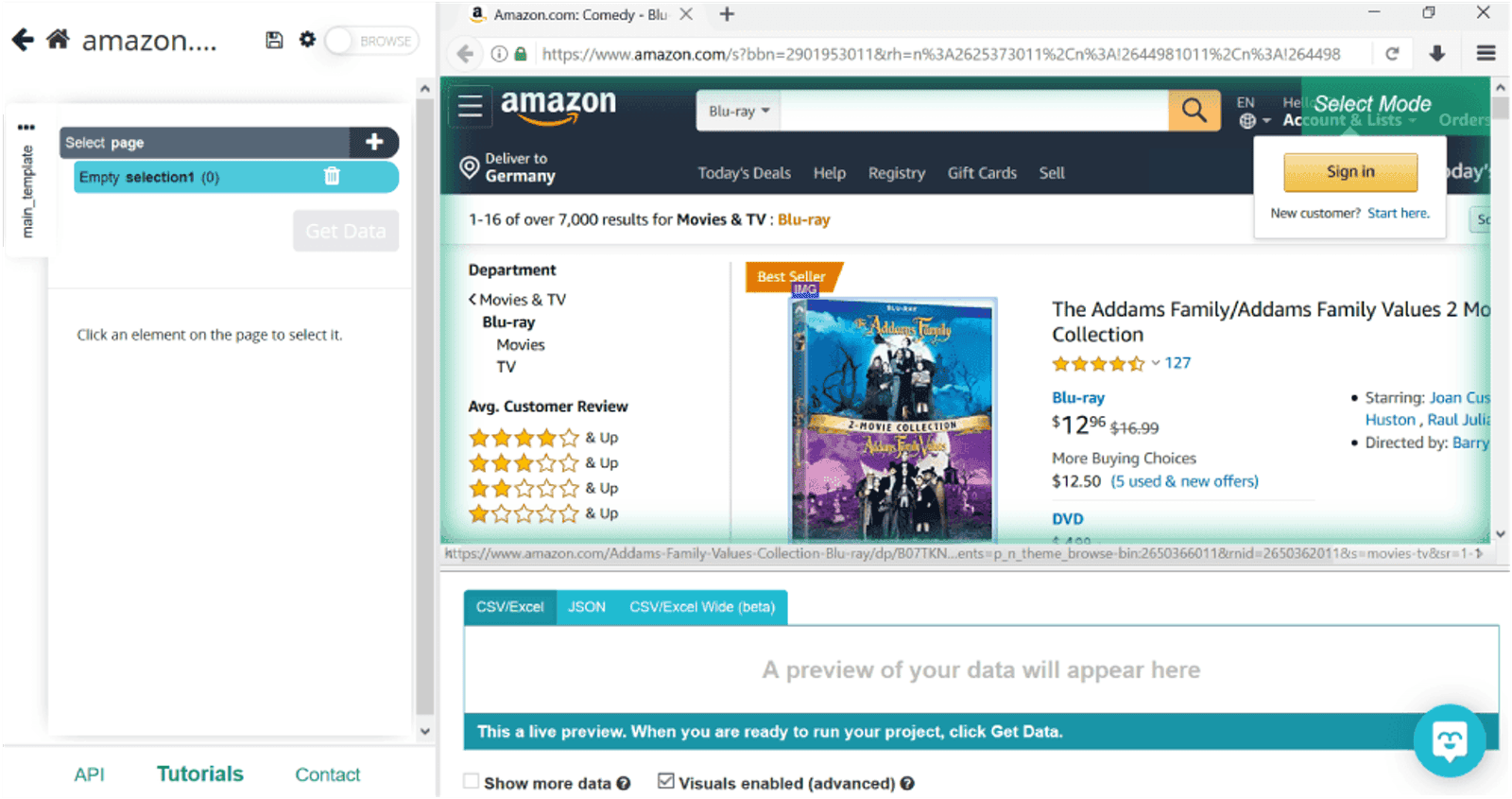
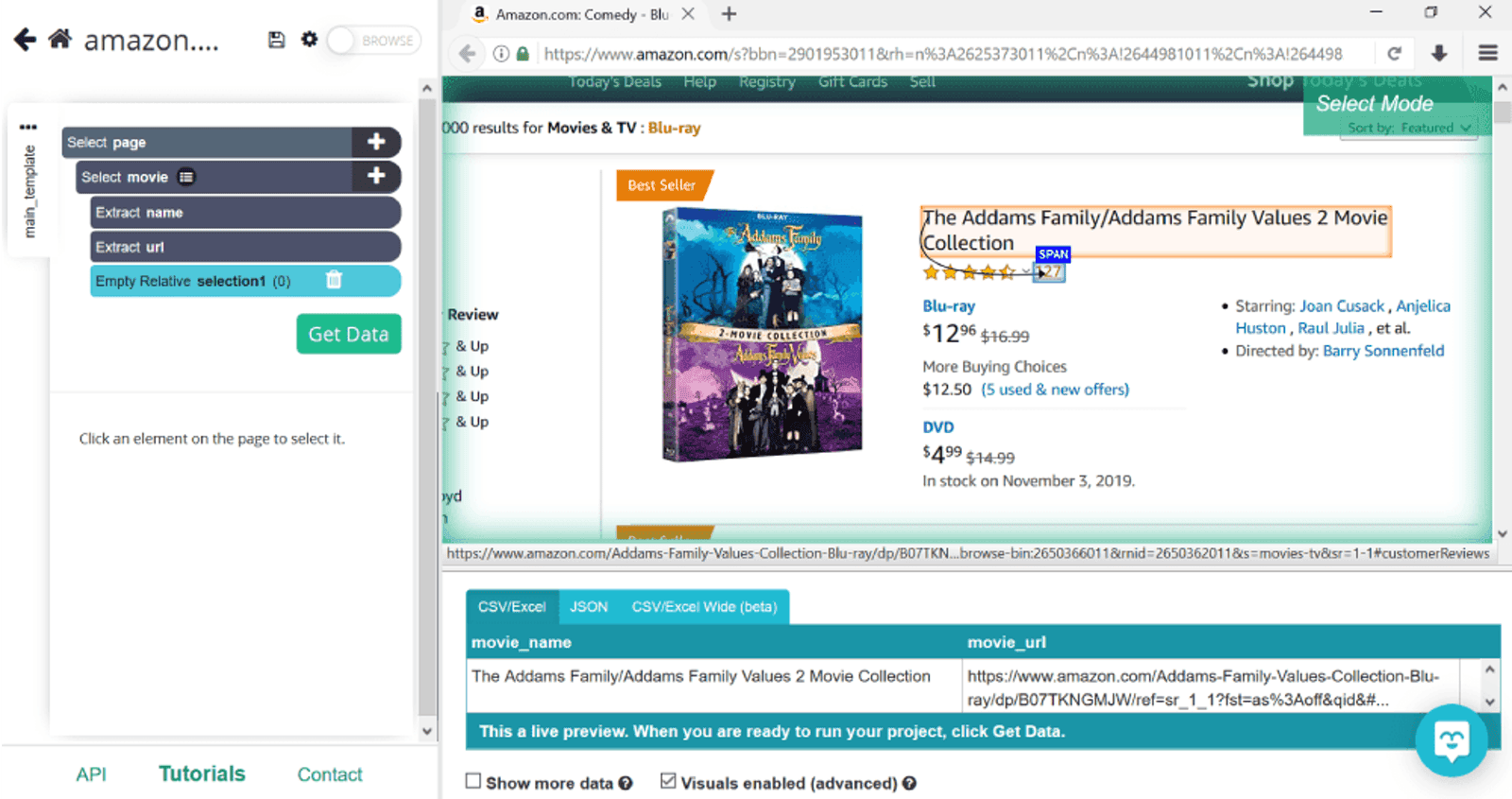
Let’s start by selecting the first piece of information - the movie titles. To do so, we’ll click on the first one, The Addams Family. To let ParseHub know that we need all movie titles to be collected, we’ll click on the second one, Yesterday.
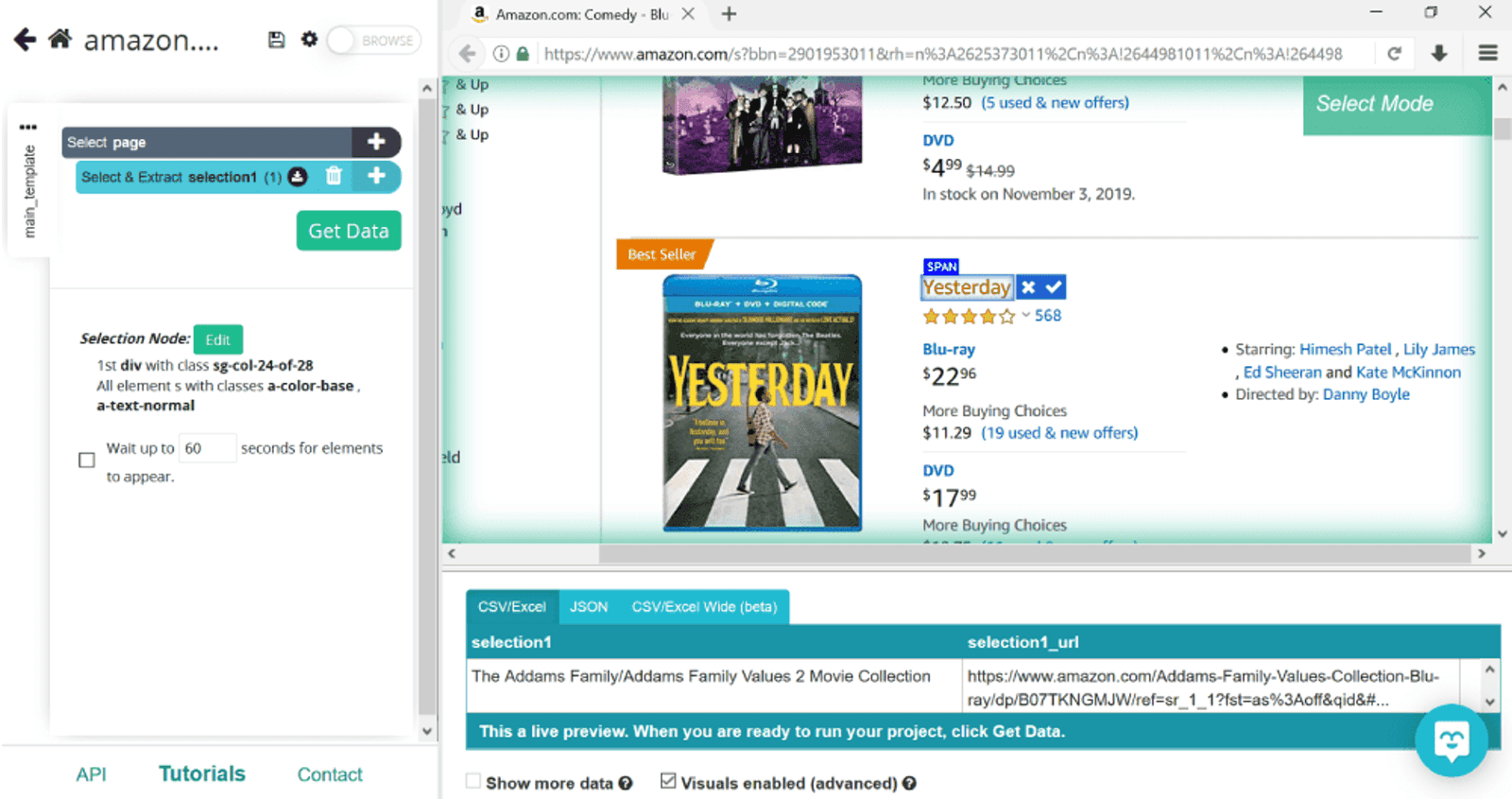
We’ll rename selection1 to be more informative and call it movie. Notice the numbers next to it: they have gone up from 1 to 16 as ParseHube adds more titles.

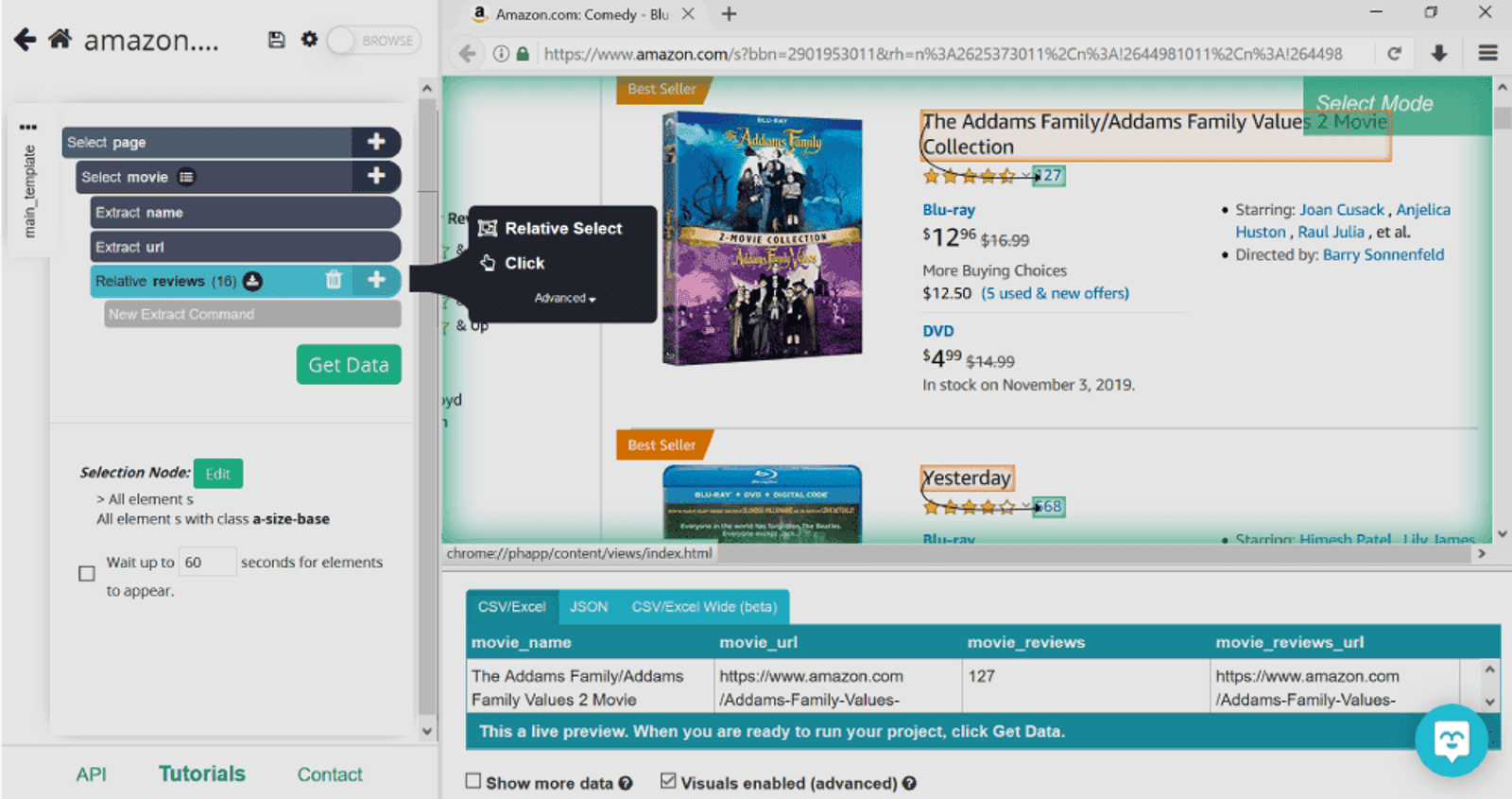
Now that ParseHub knows we’re into movies, we’ll tell it to collect number of reviews for each one. For this, we’ll be using Relative Select command. Click on the plus sign next to movie (ex selection1), and click on Relative Select.
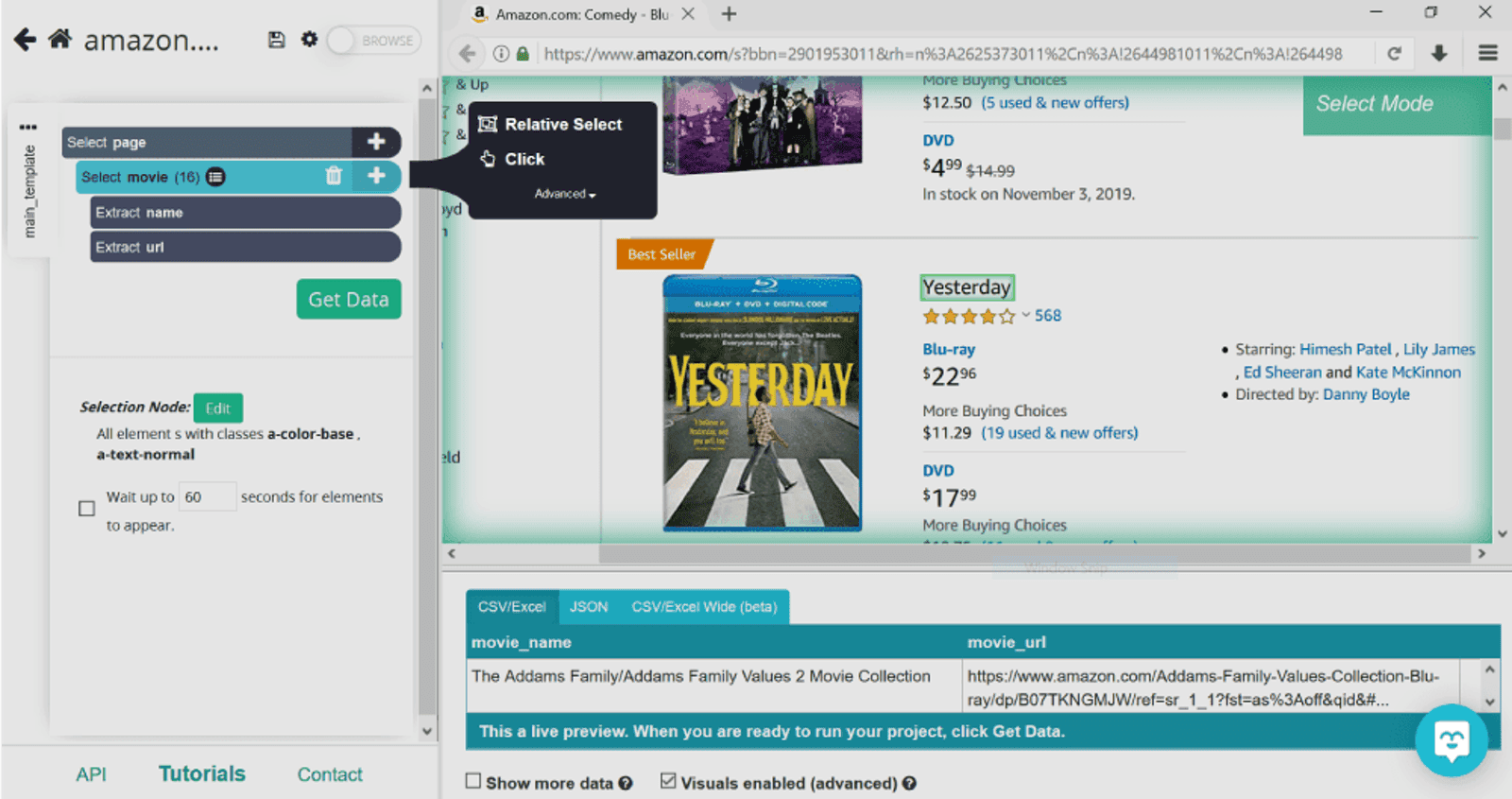
This command lets you to select information related to the products (it’s called relative select for a reason, duh). As soon as we select the movie title, ParseHub will prompt us to click on the information related with an arrow. Once we do this with the first movie, we’ll do this again with the second one to make sure that the rest of the information is collected as well.
Pro tip: By default, for each item selected, ParseHub will extract the text and URL. If you don’t need the URL for some of the categories, you can extract the text only. For example, we don’t need the links to numbers of reviews, so we’ll click on the plus sign next to the selection named reviews, select Advanced, and then Extract. This will extract only the text aka number of reviews.
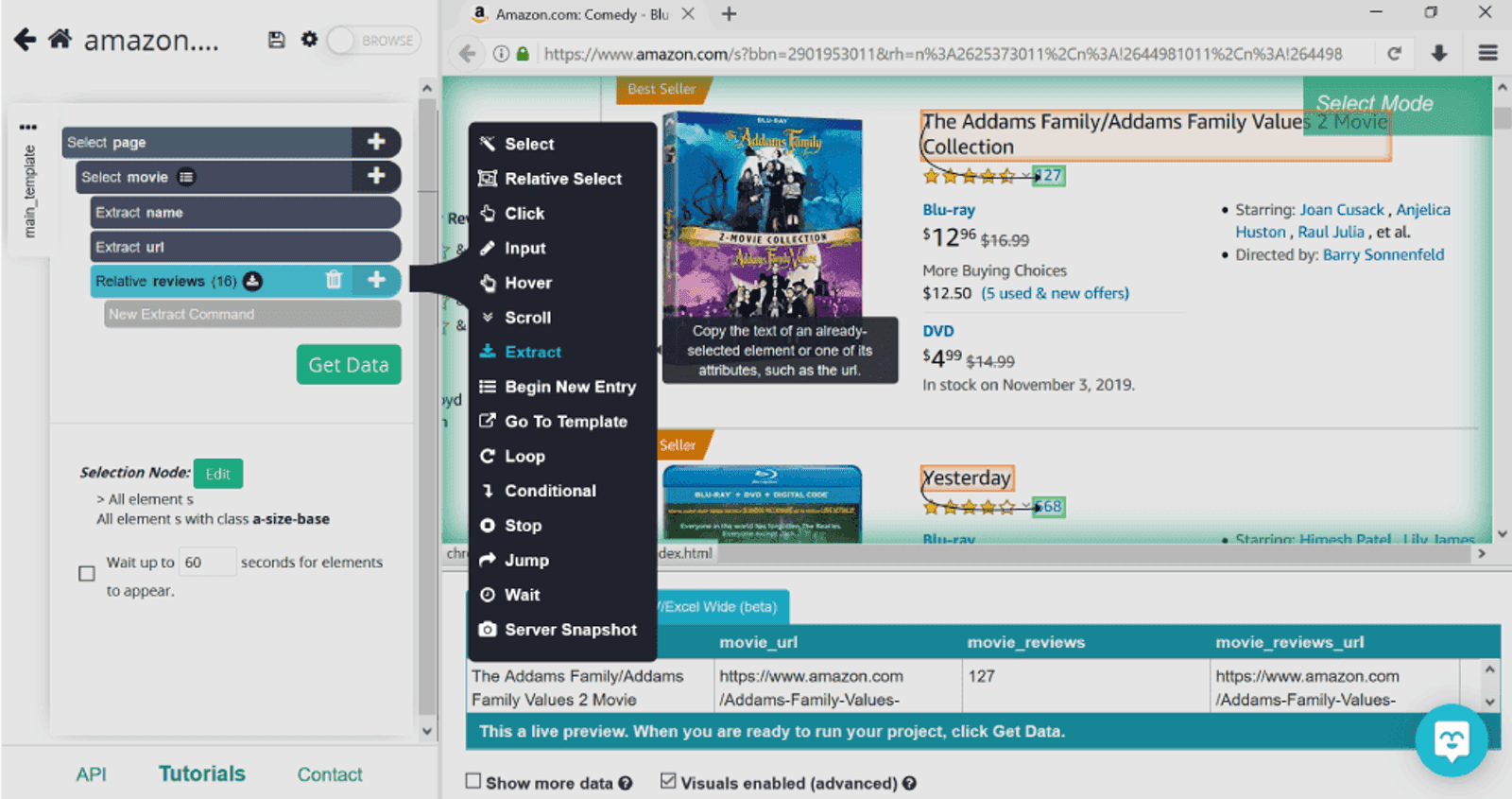
You can repeat the Relative Select command for as much information that’s available on this particular page by repeating the same actions.
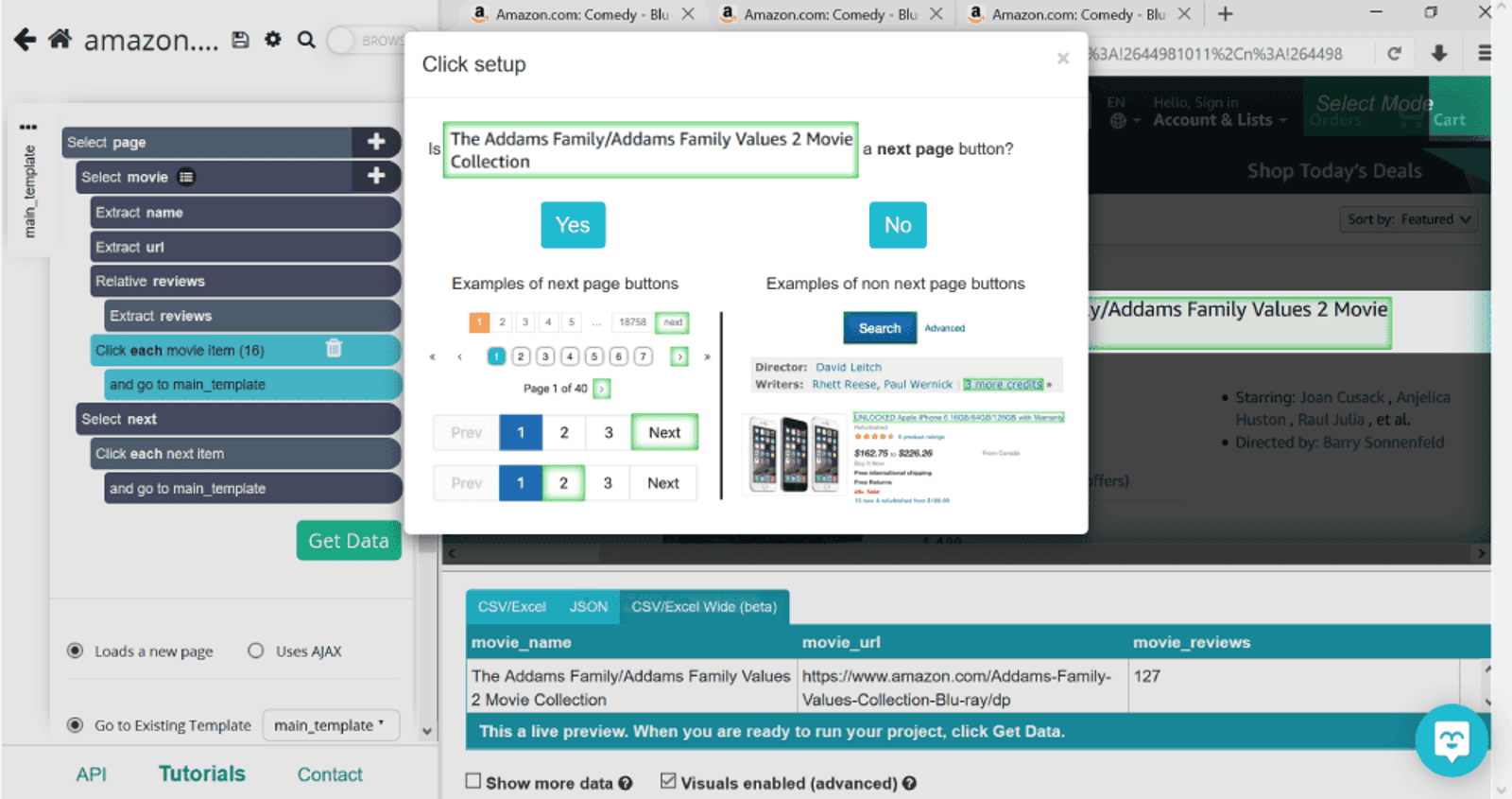
Now that we’ve got the information needed from the first page, we’ll need to tell ParseHub to repeat the same action for the rest of the pages. For this, we’ll click on the plus sign next to page and select Click command. When we click on Next, a pop up will appear, asking to confirm if the button selected prompts the next page.
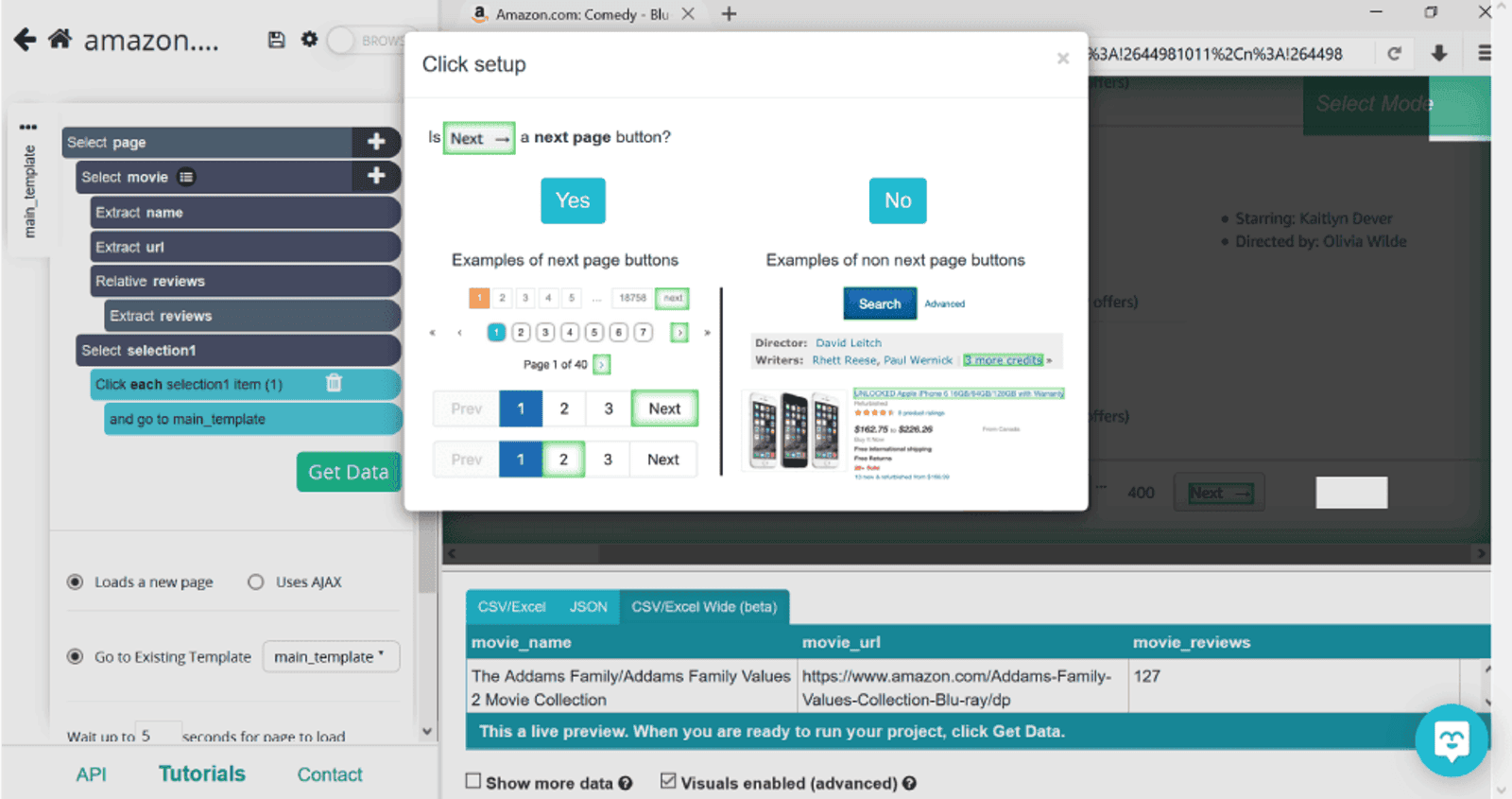
Click on Yes. ParseHub then will go on to double check if you want to repeat the same action as on the first page i.e. repeat the current template. If you want all pages to be scraped the same, leave 0, if not, specify the number of pages.
Scraping Product Pages
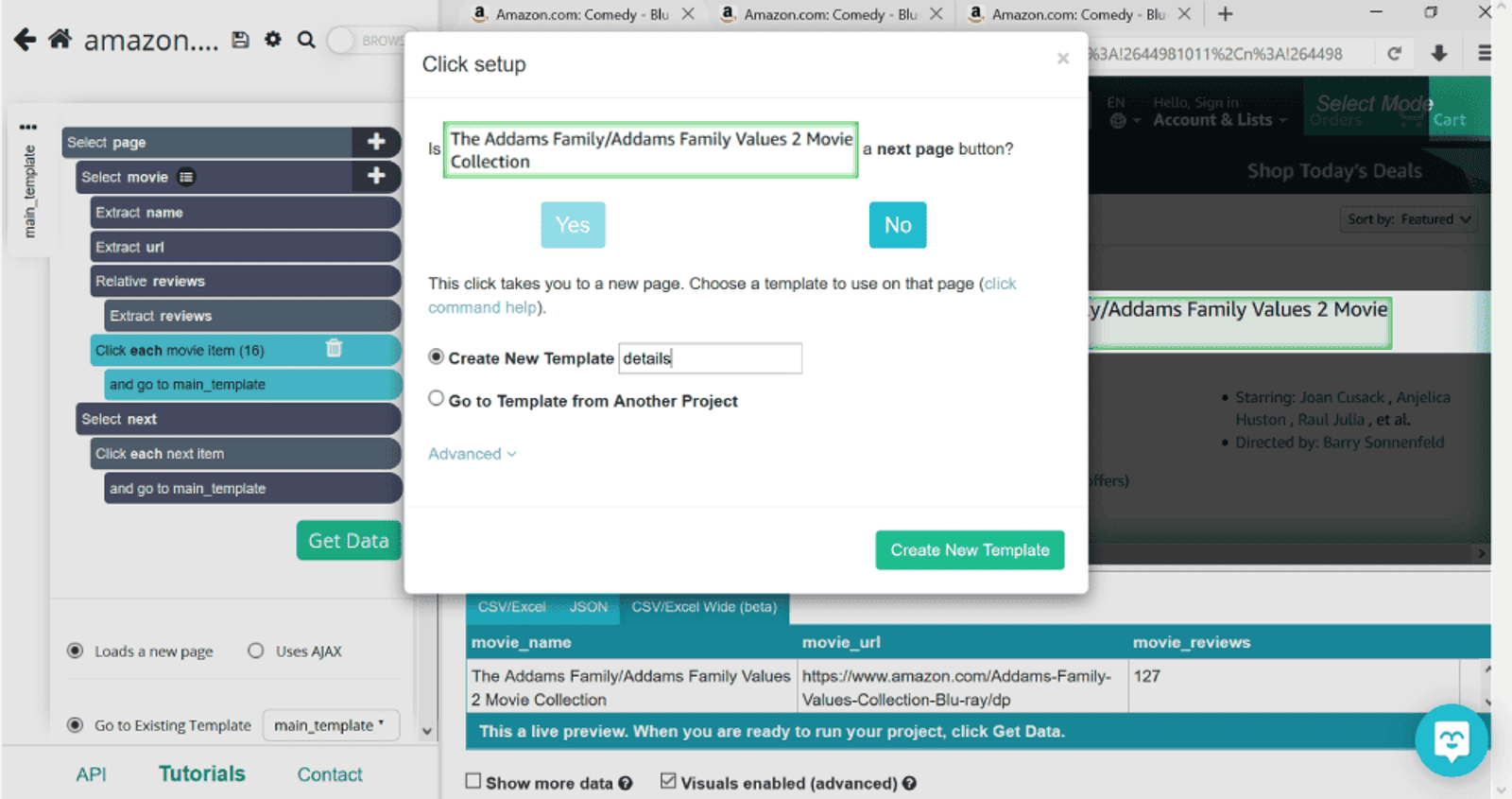
Moving on, we’ll need to collect some more specific information from individual product pages. To do this, once again, we’ll select the Click command and select the first movie title, The Addams Family. However now, when asked if it’s a next page button, we’ll click on No. This will give us an option to create a new template given that the layout of the product page is different than the list view that we started with. We’ll name this template details and click on Create New Template.
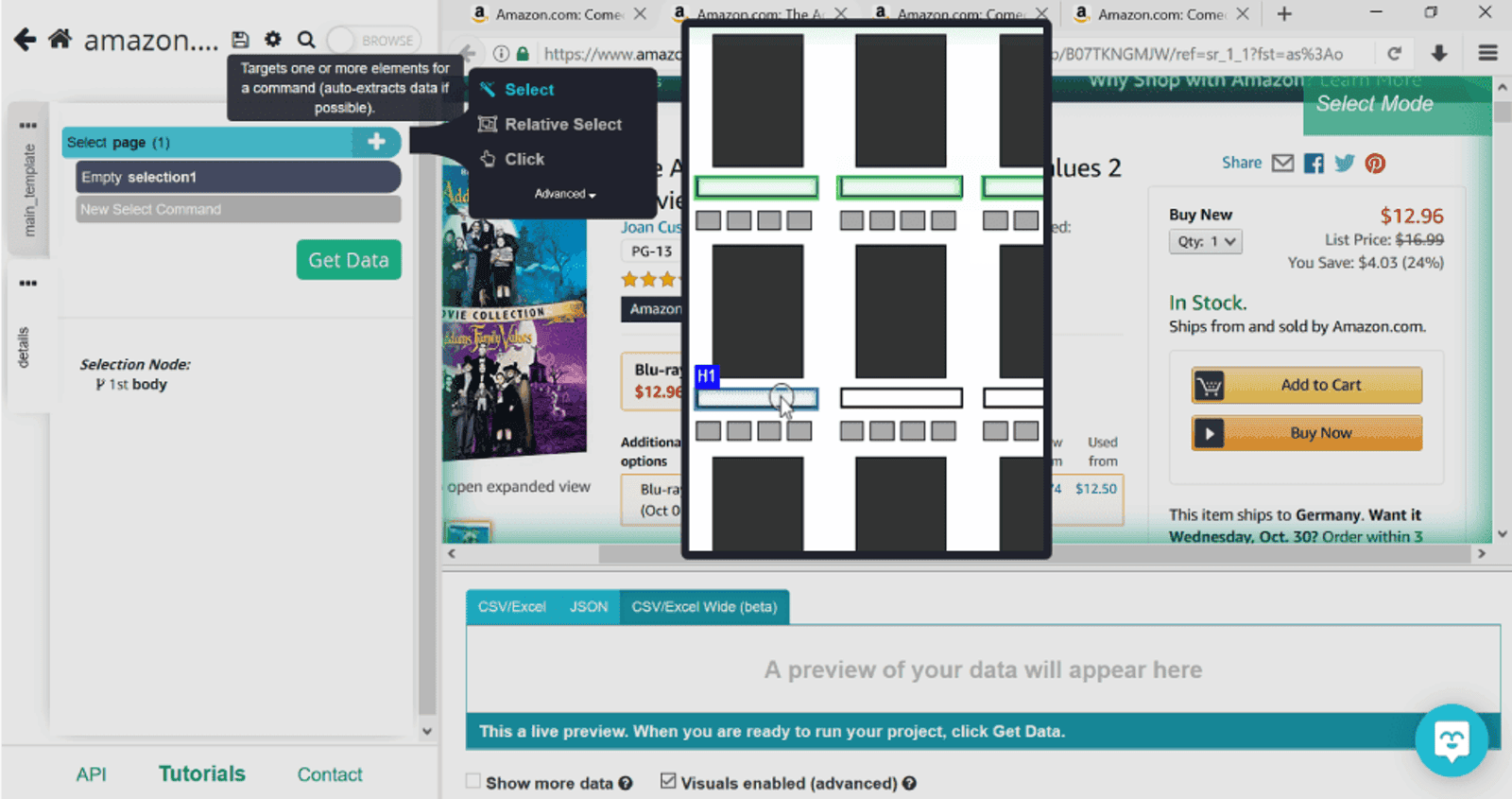
You’ll notice that on the left hand side we have two tabs: main_template and details. From here on, we’ll be working with the details tab. The first piece of information we need is the price. Click on the plus sign next to page and then Select. Notice that there’s no need to use Relative Select for this step. You’ll notice that there’s another selection added on the left that we’ve renamed price.
You could repeat this step in the same fashion with any information that would appear on each product’s page at the exact same spot. However, if you wanted to extract information from the section product details below, you’d have to use a conditional command. Why, you wonder? That’s because the order of details given might differ from product to product.
Let’s say that all we need from the product details section are the names of directors. We’ll use the same Click command to select the first piece of information given (in this case, Actors). This will highlight the rest of the categories as well, so we’ll select the second one too so ParseHub would know to look for directors in this particular section.
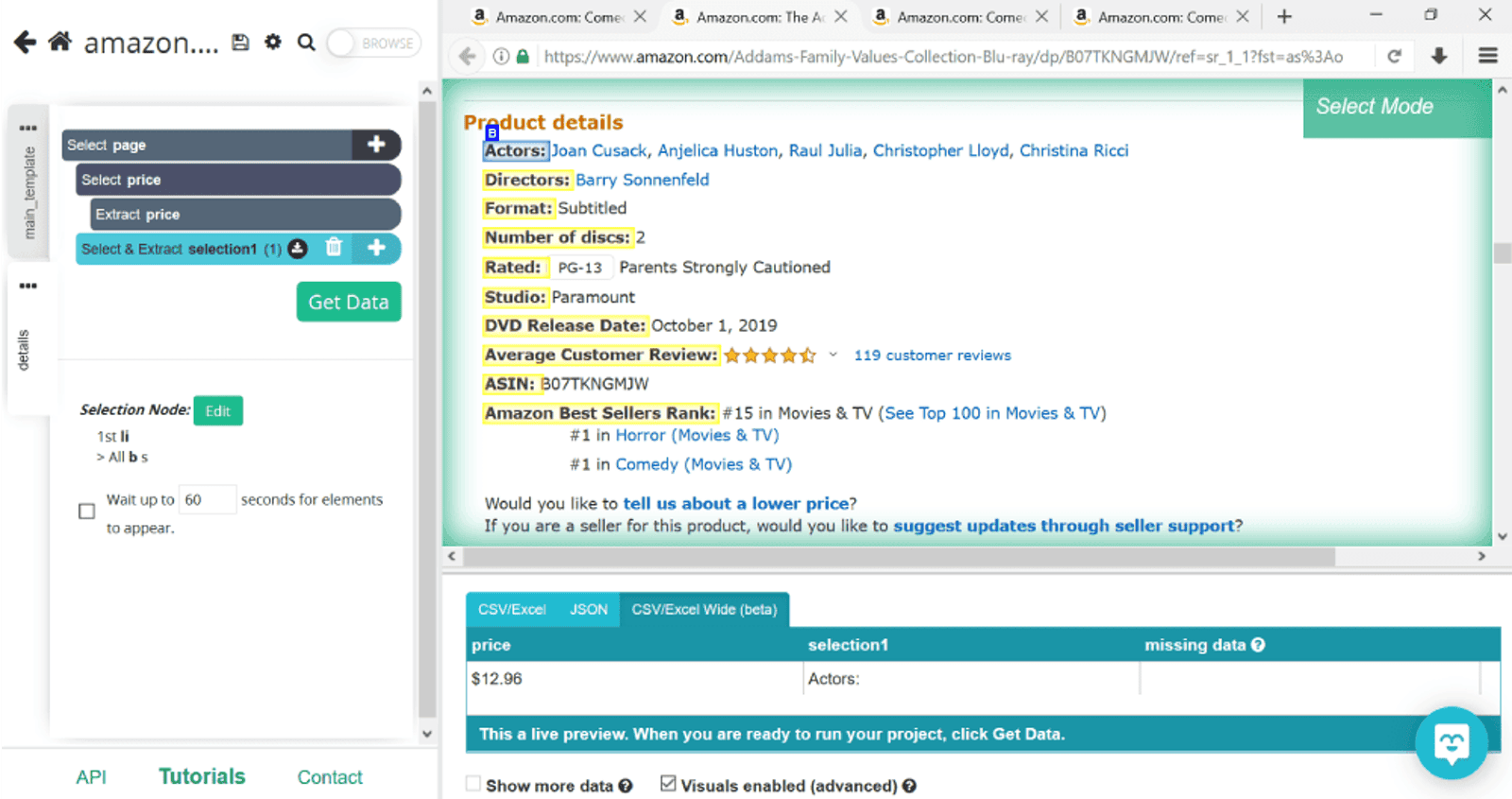
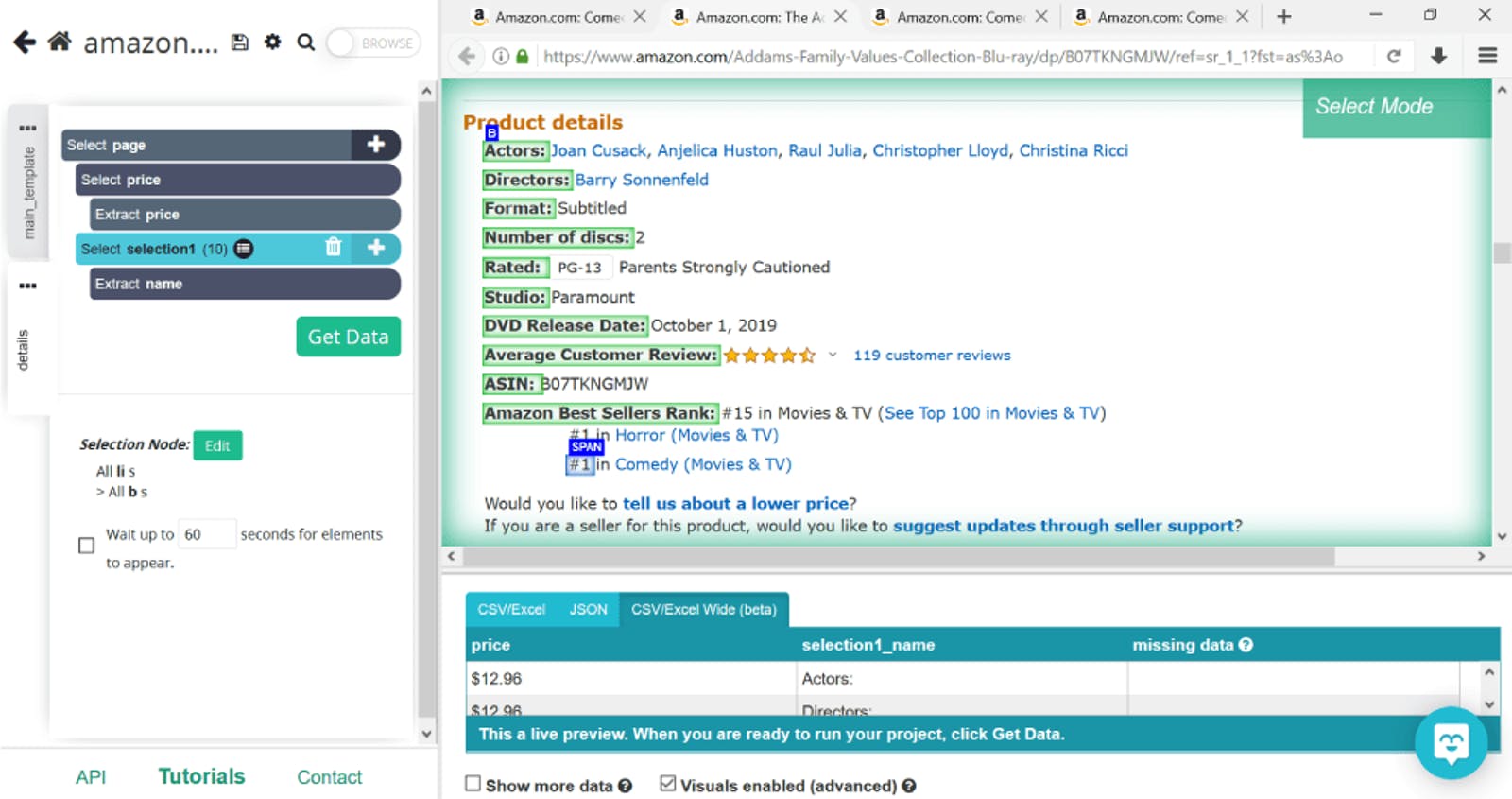
Next, we’ll create a conditional command to let ParseHub know that we only need the names of the directors extracted from the list. To do this, click on the plus sign next to selection1 (we’ve renamed this director), then select Advanced and Conditional.
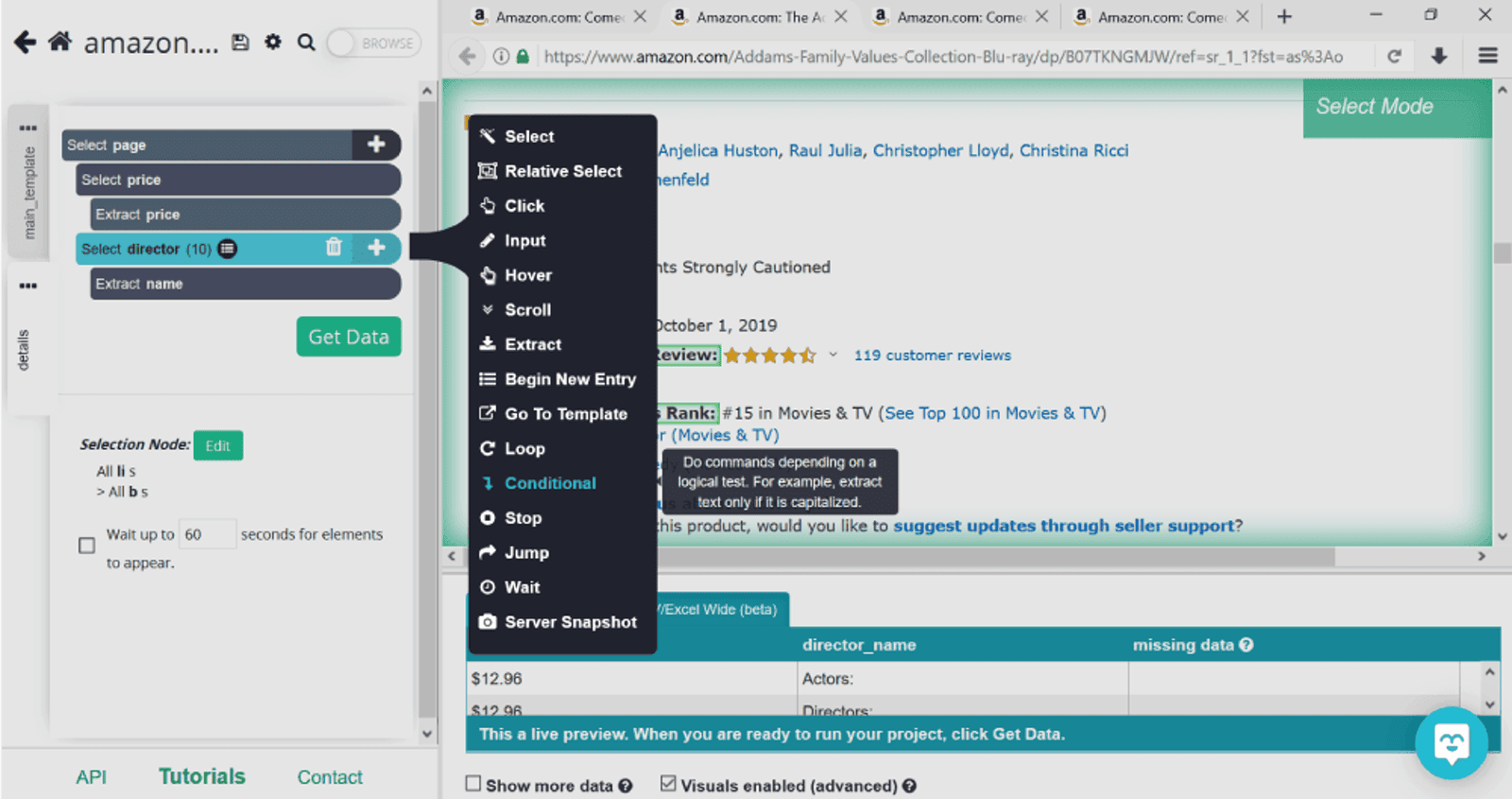
You’ll notice a box appear in the lower left corner titled Expression. This is where we put in the condition that ParseHub will need to follow when looking through the rest of the pages. Our condition will be as follows: if the text contains the word directors, then you need to get me the text next to it.
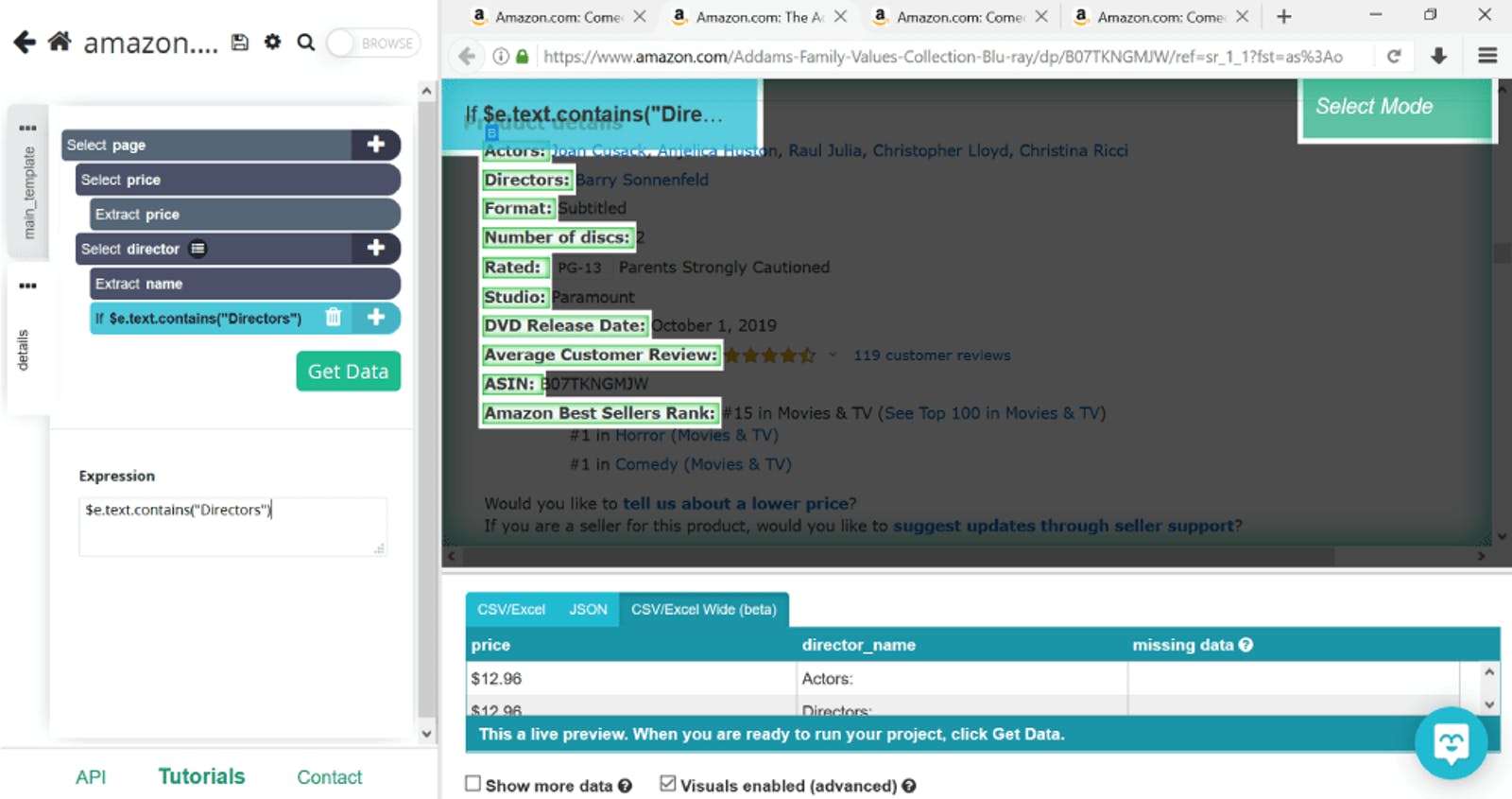
In code terms this condition looks like this: $e.text.contains(“Directors”). Don’t panic - this is the only line of code we’ll use in this tutorial. And, c’mon, it’s not that hard, just copy and paste it into your project (just change the term that meets your condition, of course). Keep in mind that this command is case sensitive so make sure you put the word exactly as it’s written on the product page.
To select the actual name of the director, we’ll use the Relative Select command. We’ll click on Directors and the text we need extracted (in this case, Barry Sonnenfeld). This will prompt ParseHub to look for the word directors in every product’s page and if found, scrape the name of the guy.
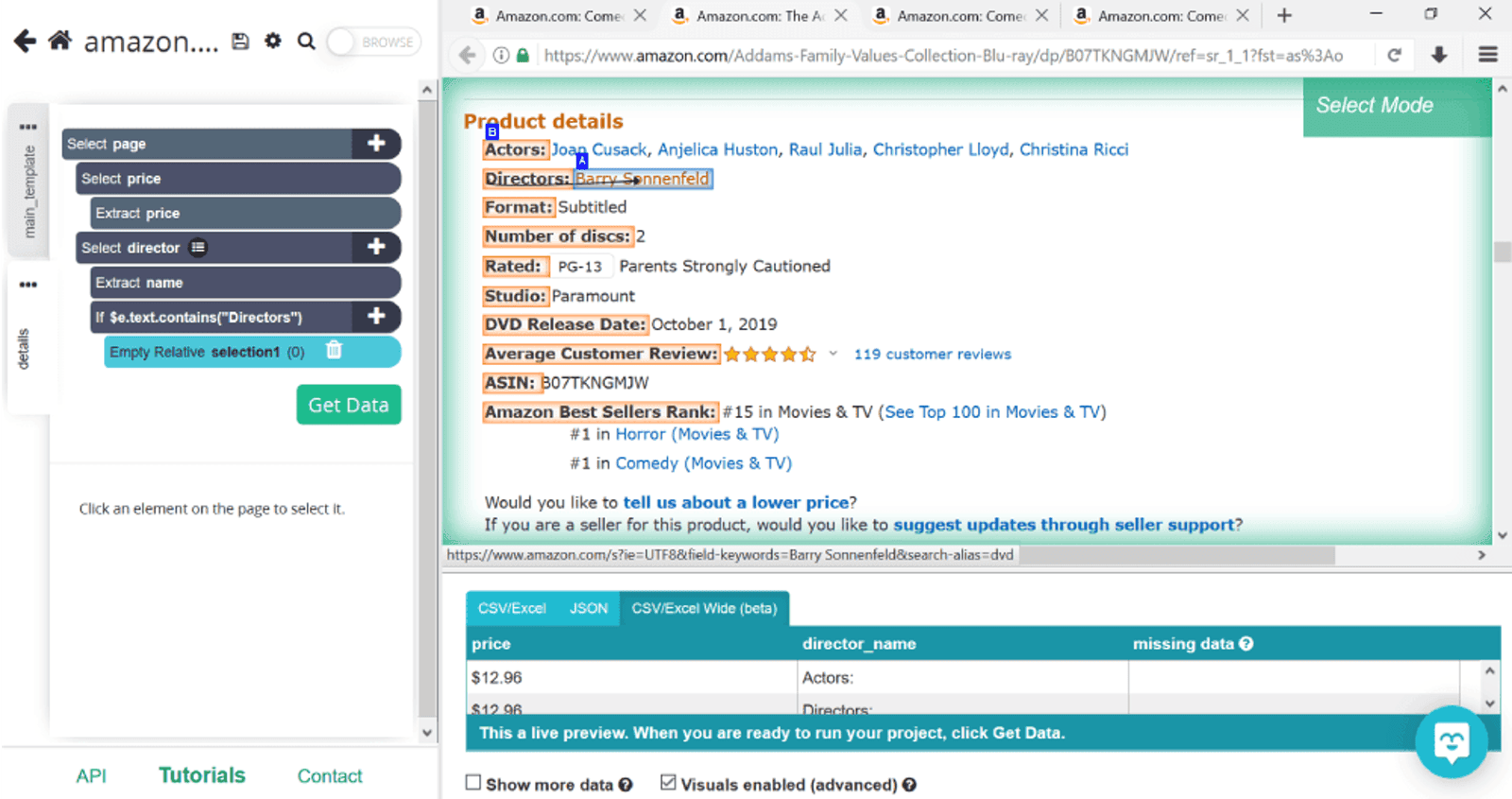
Again, you can repeat these steps for each piece of information you need, but we say it’s enough for this project. Let’s see this bad boy in action.
Before letting ParseHub loose, we’d always recommend to test it first to see if it’s functioning correctly. To do so, click on Get Data on the left hand side, and then select Test Run. This will let you see your project in action, highlighting every step that it takes.
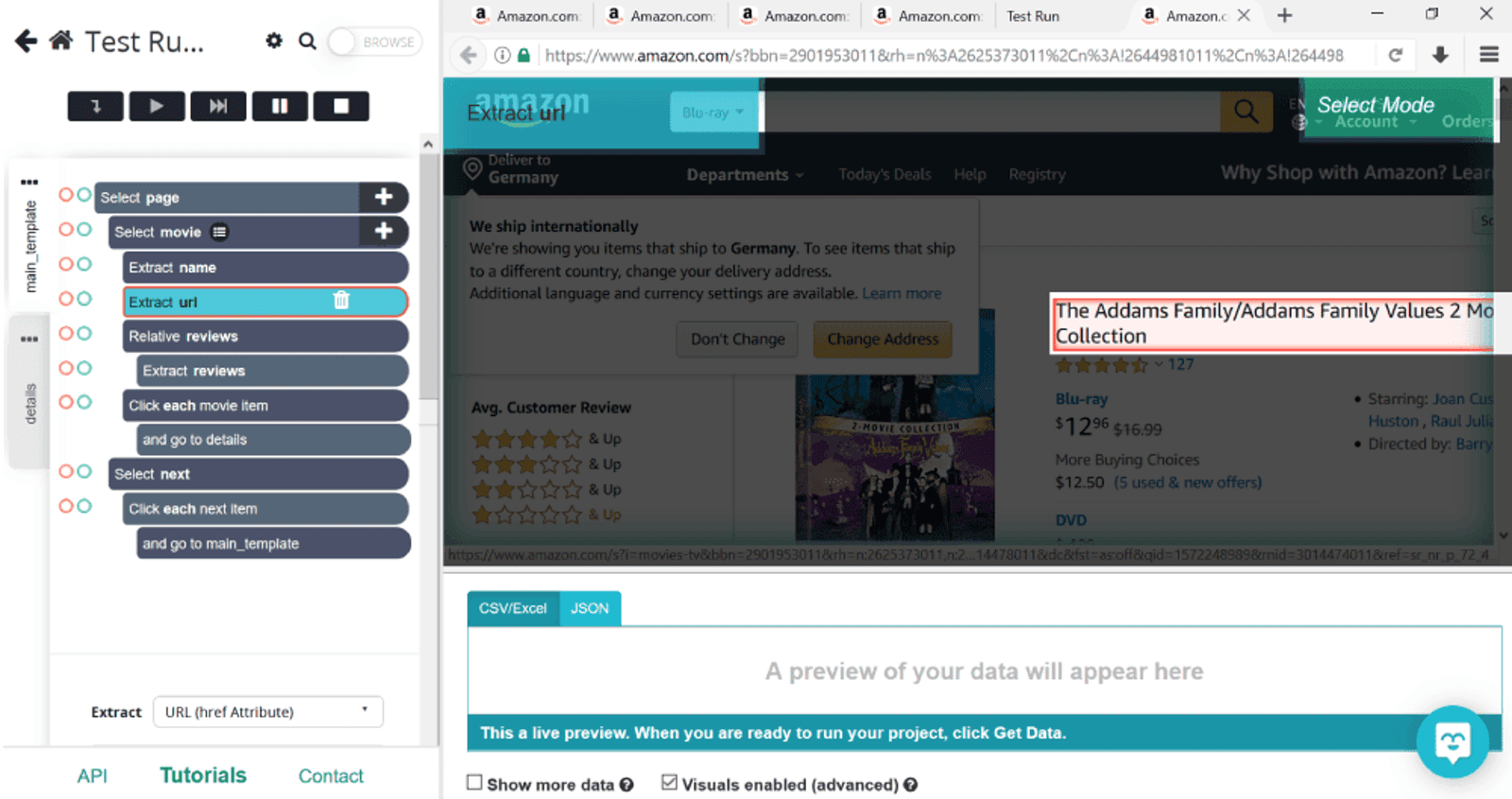
If you like what you see - and we definitely do - you can stop the run (using the square stop button on the left) and get down to the real stuff. This brings us back to the same Test Run page, but this time, we’ll be selecting Run. Now all you have to do is sit back and let ParseHub do it’s thing.
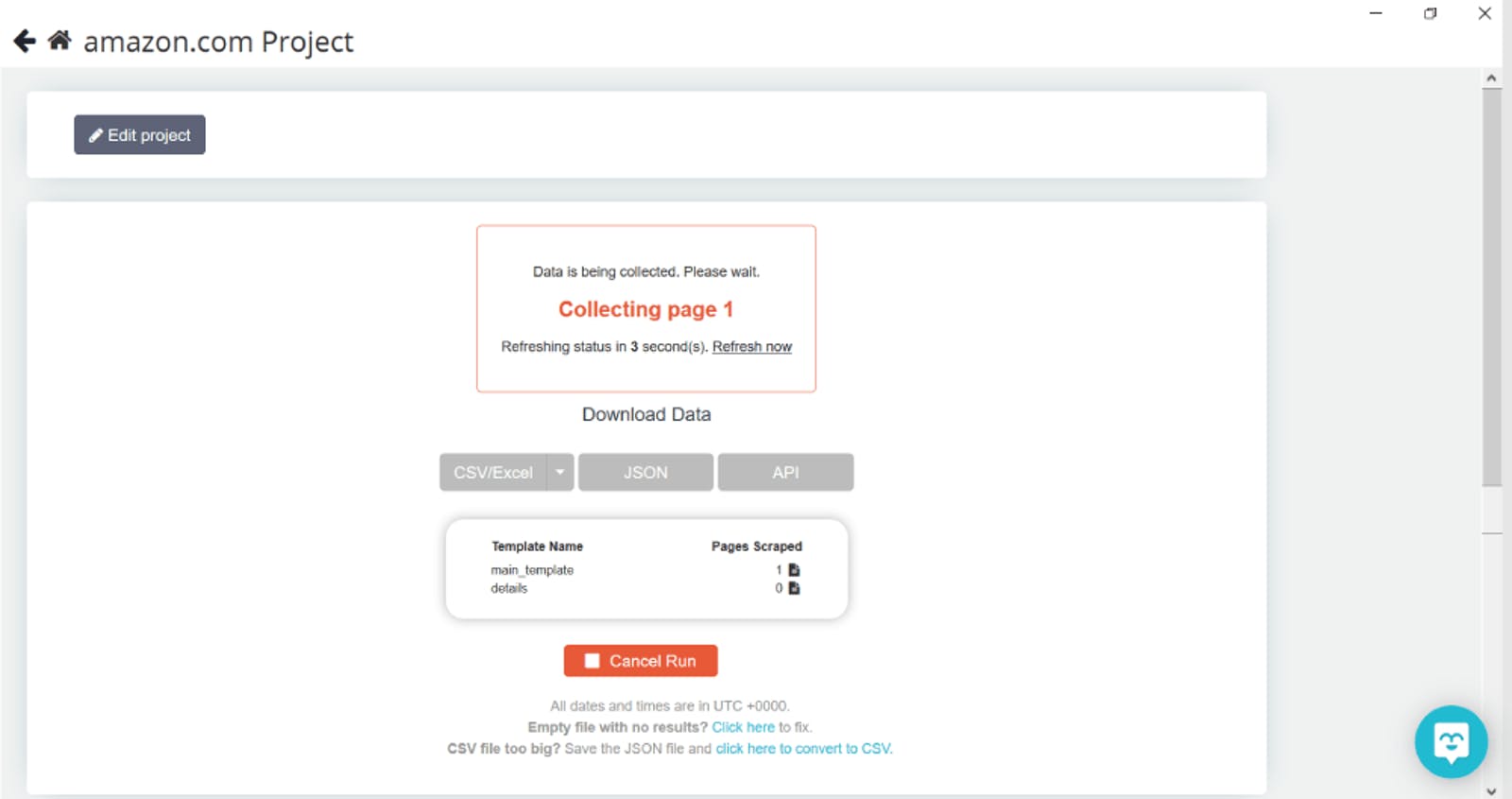
Once all data is collected, we’ll select the format we need (CSV/Excel, JSON or API) and download it. Easy, right?
If you want an easy, but very valuable addition to your market research, you have to try ParseHub. We’d say it’s meant for those who like to work smart, not hard.
Frequently Asked Questions about Scraping Amazon
Is web scraping legal?
When you are web scraping publicly accessible factual data, it is legal. Always read and follow your target's Terms of Use and robots.txt file. Always consult your lawyer before scraping a target.
Is scraping Amazon legal?
Even though Amazon doesn't preach it, scraping Amazon is legal. Prices, reviews and what-not are all available to everyone anyway.
Why do I need proxies for scraping?
When you run a scraping project from one IP address, your target website can easily clock it and block your IP. Residential scraping proxies enable you to conduct your market research without any worries.