Navigating Anti-Bot Systems: Pro Tips For 2025
With the rapid improvements in artificial intelligence technologies, it seems that 2025 will present some new challenges for web scraping enthusiasts and professionals. Over the years, anti-bot systems have become increasingly sophisticated, which makes extracting valuable data from websites a true challenge. As businesses intensify their efforts to protect against automated bots, traditional web scraping methods are being put to the test. The surge in anti-bot measures is not only due to heightened cybersecurity awareness but also signifies a shift in the digital ecosystem and growing competition. As a result, those who want to leverage publicly available data need to recalibrate their strategies to navigate and circumvent anti-bot systems.
If CAPTCHAs and IP bans were not on your bingo card for 2025, our comprehensive guide is a must-read. We’ve sat down with our scraping gurus and discussed the best practices, gathered all the pro tips, and summarized what’s coming next for anti-bot systems and scrapers. As 2026 approaches, it demands a proactive approach to understanding, outsmarting, and ultimately thriving in the face of escalating anti-bot measures, so grab a cup of coffee and dive into our guide.
If you can't access the whole article, make sure you have disabled your ad blocker

Vilius Sakutis
Dec 15, 2023
11 min read
Understanding anti-bot systems
An anti-bot system is a crucial tool for virtually every website to ensure a smooth user experience. It is designed to detect and thwart the actions of automated programs, aka bots. These bots can range from amiable ones, such as search engine crawlers, to the ones that might slow down the website speed, like automated data scrapers, click fraudsters, or distributed denial-of-service (DDoS) attackers. The core purpose of anti-bot measures is to identify which actions on the websites are taken by real users and which are automated scripts.
Exploring standard anti-bot measures employed by websites
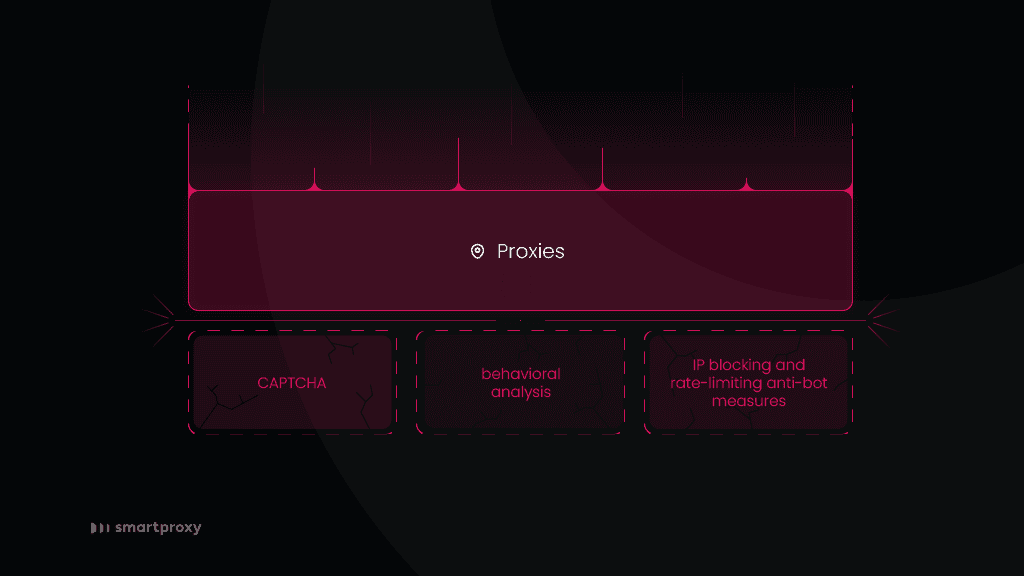
Websites deploy various anti-bot measures to fortify their defenses against automated visitors. From the most popular ones that every internet user has faced at least once to advanced AI-powered anti-bot systems, counting them all might take a while.
- One of the most popular and well-known defence systems is a CAPTCHA. It presents a user with a challenge that demands human-like responses, like solving puzzles or entering distorted characters.
- Behavioral analysis is another common approach. By utilizing behavioral biometrics to separate between human and bot actions based on interaction patterns, these systems identify real users and block bots that don’t meet the criteria.
- Restriction measures like IP blocking and rate-limiting are also prevalent, restricting the number of requests from specific IP addresses to impede bots from overwhelming servers.
Advanced anti-bot systems incorporate machine learning algorithms, enabling them to adapt to evolving bot tactics dynamically. These systems analyze real-time patterns, user interactions, and device information to assess whether an action originates from a regular internet user or a bot. This continuous learning process enhances the precision of bot detection over time.
Why do websites implement anti-bot systems?
Implementing anti-bot systems is driven by various motivations, with smooth user experience and security standing out. The main purpose of such systems is to uphold a positive user experience by preventing bots from disrupting services, causing website slowdowns, or engaging in activities that hinder genuine user interactions.
Security considerations are equally important, as bots can be exploited for malicious purposes such as searching for unauthorized access and credential stuffing attacks. According to Arkose Labs, 73% of all internet traffic between January and September in 2023 was attributed to bots engaging in malicious activities. Anti-bot systems mitigate these risks and safeguard sensitive information.
From the eCommerce side, the motivation extends to maintaining fairness between all online shoppers. Anti-bot measures prevent automated bots from bulk-buying limited-quantity items during sales or manipulating demand.

The true anti-bot impact on web scraping
Anti-bot measures also significantly influence web scraping activities. While some scraping is conducted for legitimate purposes, like research or market analysis, not all scraping cases are white hat. Malicious scraping activities can lead to data breaches or stolen intellectual property.
Anti-bot systems pose challenges for web scrapers, pushing the developers to continue searching for sophisticated techniques to mimic human behavior and avoid detection. Finding a balance between preventing malicious scraping and permitting ethical and legal web scraping practices remains vital.
How do we bypass anti-bot systems?
Getting around anti-bot systems has turned into a bit of a tricky game for web scraping experts. They're up against the ever-changing methods companies use to detect and block automated activities. Companies aim to protect their data and servers from potential harm, so they're rolling out sophisticated anti-bot solutions. In response, web scraping enthusiasts are always tweaking their strategies to slip under the radar, using various tricks to ensure their scraping activities aren't flagged.
One smart move in playing around the anti-bot systems involves copying human behavior. This means making requests to target websites in a way that looks like regular browsing, such as mixing up the timing and order of requests, random mouse movement, scrolling, and various delays. By acting more like a human user, scrapers hope to dodge detection algorithms looking for repetitive and robotic patterns, letting them sneak past the defenses set up by anti-bot systems.
Dealing with CAPTCHAs, those puzzles designed to tell humans and bots apart, has led to some pretty advanced techniques. Web scraping professionals use machine learning and optical character recognition (OCR) technology to solve CAPTCHAs automatically. This lets scrapers tackle one of the toughest challenges in the anti-bot world, ensuring their activities stay unnoticed even when faced with increasingly tricky challenge-response systems.

Pro tips from web scraping experts
Entering the world of web scraping requires tech skills, strategy, and a sense of current trends. And when you’re up for a scraping challenge against anti-bot systems, there’re even more things you should consider. To help you on this journey, we’ve gathered the best tips from scraping gurus.
Tip #1 Leveraging rotating proxies
An important part of successful data collection around anti-bot systems is using rotating IPs. Anti-bot solutions often keep an eye on and block IPs connected to suspicious or excessive activity. To counter this, web scraping experts equip themselves with high-quality residential proxies, letting them switch IP addresses. This makes it challenging for detection systems to catch on and block their scraping activities. The strategy of constantly switching IP addresses adds an extra layer of complexity for anti-bot systems, forcing them to keep up with the ever-changing network patterns of web scrapers.
Tip #2 Equipping high-tech scraping tools
Such tools act as your digital ally, offering a range of features that can significantly enhance your scraping game. Tools like Site Unblocker have a built-in scraper, JavaScript rendering, and a user-friendly, browser-like experience. Users can integrate Site Unblocker into their code with a single endpoint or get results using a convenient interface in the Decodo dashboard.
Tip #3 Using advanced browser fingerprinting
Advanced fingerprinting is a technique commonly used by seasoned users who collect publicly available data from targets that employ multiple anti-bot systems in their websites. Fingerprinting includes replicating various headers that a browser sends to a website, such as browser type, operating system, screen resolution, and cookies, making the scraping activity appear more human-like. Utilizing cutting-edge browser fingerprinting enhances the scraper's ability to avoid detection and contributes to a more seamless and successful data extraction process.
Tip #4 Keeping up with the trends
The most important aspect all of the scraping professionals outlined is that the industry is ever-changing and evolving. Together with the industry, the anti-bot systems are getting more advanced, and what has worked today might not work tomorrow. Following the recent developments and adjusting your scraping toolbox is vital. However, if you’re sort of a one-off data collector, scraping gurus recommend using third-party tools that constantly improve with the changes in the industry.
Wrapping up
Extracting relevant data from various targets while avoiding increasingly sophisticated anti-bot systems demands a proactive and adaptive approach.
As expected, our guide concludes with a reminder that success in web scraping hinges on a combination of technical expertise, strategic thinking, and a healthy awareness of the ever-changing anti-bot landscape. By leveraging rotating proxies, high-tech scraping tools, advanced browser fingerprinting, and staying abreast of industry trends, web scraping enthusiasts can navigate and thrive in the face of escalating anti-bot measures.
The journey through anti-bot systems may be complex, but with the right knowledge and tools, data can unlock the secrets to the success of almost any industry.
About the author
Vilius Sakutis
Head of Partnerships
Vilius leads performance marketing initiatives with expertize rooted in affiliates and SaaS marketing strategies. Armed with a Master's in International Marketing and Management, he combines academic insight with hands-on experience to drive measurable results in digital marketing campaigns.
Connect with Vilius via LinkedIn
All information on Decodo Blog is provided on an as is basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Decodo Blog or any third-party websites that may belinked therein.