

Amazon Product Data Scraping with Datacenter Proxies
This comprehensive guide will explore the powerful capabilities of Smartproxy's datacenter proxies for scraping Amazon product data. Whether you're an eCommerce professional, researcher, or developer seeking to extract those juicy insights from Amazon's marketplace, you'll discover how Smartproxy's datacenter proxies can be a cost-effective solution to enhance your workflow, improve results and conquer any typical obstacles encountered while web scraping.


%20(1).png?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max&rect=0%2C0%2C2000%2C2000&w=95&h=95)
Martin Ganchev
Oct 30, 2023
15 min. read



Understanding Amazon scraping
Scraping the Amazon website can be incredibly useful for your eCommerce business. Market research conducted through Amazon scraping provides valuable insights into consumer preferences, trends, and product demand. Pricing intelligence helps you set competitive prices and stay ahead in the market. Finally, competitor analysis allows you to track other companies' strategies, product offerings, and customer reviews, allowing you to identify their strengths and weaknesses. You can see why scraping Amazon data is a powerful tool that can empower your business to adapt and thrive in eCommerce.
Such treasures aren’t easy to reach, however. There’re many obstacles, traps, and enemies you must overcome first before getting the golden chests of Amazon data. While it’s okay to scrape publicly available data, Amazon will often block automated requests that aren’t coming from real humans, issue IP bans, require you to solve CAPTCHAs, and rate-limit your requests. You’ll need the best gear to get to the valuable loot.
A reliable proxy solution is the best answer to scrape product data from Amazon effectively. It allows you to make multiple requests from different locations and appear as a real user while maintaining complete anonymity and avoiding any of the challenges mentioned above.
Introducing Smartproxy's datacenter proxies
Smartproxy offers datacenter proxy services that are perfect for web scraping. These proxies are fast, reliable, and easily scalable, making them an ideal fit regardless of whether it’s a small or big project (or a small project unexpectedly growing into a big project).
Datacenter proxies are built on remote servers, which are faster, more stable, and more powerful than proxies built on regular computers or mobile devices. They are a perfect fit for Amazon scraping projects, as the website’s pages contain many elements and information, requiring fast response times and reliable connections to perform mass web scraping tasks reliably.
Smartproxy boasts a vast global proxy network spanning many different locations worldwide. With 100K+ IP addresses, you can be sure you’ll access Amazon’s data from various regions, reducing the possibility of your web scraping activities being linked to one location and the risk of getting blocked. The flexible pricing options are also incredibly valuable – you can choose the Pay/GB plan to pay for traffic and access the entire proxy pool or Pay/IP, which can be customized according to your needs. This means you can choose the number of IPs, the bandwidth size, and locations for a very budget-friendly price. Try it out without worrying about a thing – you have a 14-day money-back guarantee option to see if you like it.
Benefits of Smartproxy’s datacenter proxies for Amazon scraping
There’re many advantages to using Smartproxy’s datacenter proxies. First, they stand out above the rest in their high-speed connections with response times of <0.3 s, which helps you save time by performing tasks much faster. Secondly, the datacenter proxy service offers rotating IPs and sticky sessions for up to 30 minutes, meaning you won’t need to worry about multiple people using the same IP address already and potentially getting blocked by the Amazon website. Finally, the robust framework and the ability to run multiple concurrent sessions simultaneously ensure that you will face little to no downtime when web scraping.
One more fantastic thing – Smartproxy offers a large number of proxy servers to choose from and the ability to rotate IP addresses, which is a crucial feature when scraping web data. Making requests from constantly changing locations worldwide is super easy to set up through a single gateway address, and it ensures total anonymity, so you’ll never have to worry about being IP banned while web scraping.
Step-by-step guide to scraping Amazon product data
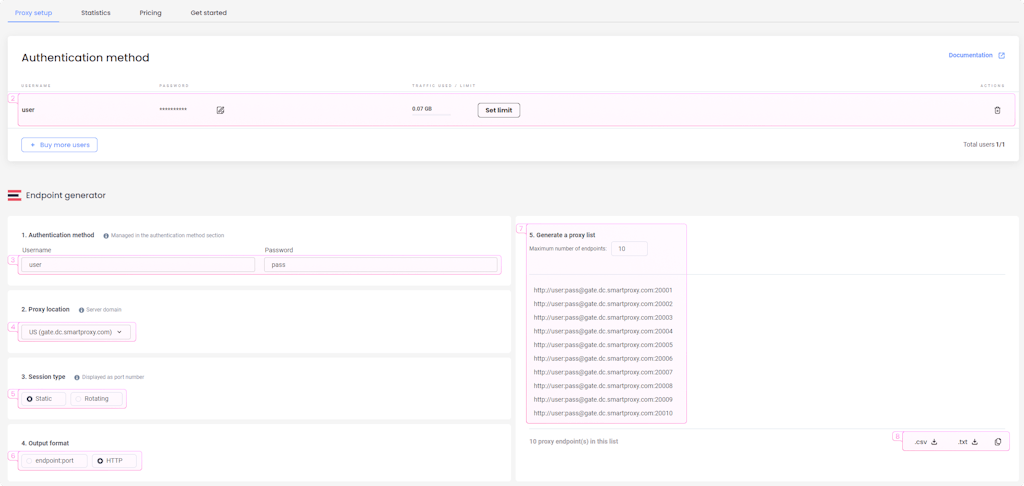
Proxy setup
To scrape Amazon data using Smartproxy’s datacenter proxies, you’ll first need to do a little setup in the dashboard.
- If you haven't done so already, grab a datacenter proxy plan that best suits your needs.
- To change your default username or password, navigate to the Proxy setup → Authentication method section. To change your password, click the Edit password icon next to it. If you want to change your username, delete the current user and create a new one with your desired credentials.
- Next, configure various settings in the Endpoint generator. Enter the same username and password from above in the Authentication method section.
- Select a Proxy location. You can choose from various countries or select All to have one assigned randomly.
- Select a Session type between Rotating and Static. If you select a rotating type, the IP address will change by itself, but you’ll have to rotate your headers with each request. Meanwhile, if you use a static session type, you shouldn’t make too many requests from the same IP address, and make sure to change your headers frequently to avoid them getting rate-limited or blocked.
- Choose an Output format. The choice depends on how and where you’ll want to implement it.
- You’ll see a list of generated endpoints on the right side. If you wish, you can increase or decrease the maximum number of endpoints to generate (only if your session type is sticky).
- Finally, save the list as a TXT or CSV file or copy it to your clipboard to save it anywhere easy to find.


Scraping the data
Once you’re finished setting up, the next step would be to choose a programming language or tools to scrape with. Many options and web scraping libraries are available, and it would be difficult to list all of them; therefore, you should research what works best for you. In this tutorial, we’ll take a beginner-friendly approach of using Python with the requests library to write simple code to scrape Amazon data.
Begin to set up your environment by installing the latest version of Python on your computer. If you’re a Windows user, add python.exe to PATH to execute Python commands from the Terminal.



Python should automatically come with pip, a package installer for Python that you’ll need to install the requests library. Run the following command in the Windows Terminal to ensure that you have it installed:
python -m ensurepip --upgrade
You will also need an IDE (integrated development environment) like the free Visual Studio Code to write and test the code. Once installed, open it and create a new file called amazon_scraper.py. Afterward, run this command in the Terminal to install the requests library:
python -m pip install requests
Finally, write the code:
# Start by importing the requests library. This helps you make HTTP/HTTPS requests to the Amazon serverimport requests# Enter your proxy information from the Dashboard. You can get the whole URL immediately from the endpoint generator by selecting an HTTP output format# Example: http://exampleuser:examplepassword@gate.dc.smartproxy.com:20000proxy_url = "http://{user}:{password}@{gateway}:{port}"# Define that you will use the same proxy URL for both HTTP and HTTPS requestsproxies = {"http": proxy_url,"https": proxy_url}# Set the target URL to scrape. Let's use a headphone product page as an example. It features all of the basic information about an item, product price, product rating, reviews, etc.url = "https://www.amazon.com/Riwbox-TX8-Bluetooth-Headphones-Wireless/dp/B09FT3KWJZ/"# Headers are what make your code look like a real person accessing the website and are the key elements to avoid being rate-limited or IP banned.# The User-Agent header is mandatory, providing basic information about your "system." Without it, you will most likely get an error result.# You will probably not get any results back just with a user agent header. The other headers are less important, but you must include at least a few to appear as a real user.headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36","Accept-Encoding":"gzip, deflate","Accept":"text/html, application/xhtml+xml, application/xml;q=0.9,*/*;q=0.8","Upgrade-Insecure-Requests":"1"}# Once you have defined everything, it's time to put it all into action. Here you are using the requests library to request the target URL with the defined headers and proxy information.response = requests.get(url, headers=headers, proxies=proxies)# Print the contents to get the resultprint(response.content)
To execute the code, simply run this command in the Terminal:
python amazon_scraper.py
If everything went smoothly – great! If not, you might’ve run into the following message right under the <body> tag: “To discuss automated access to Amazon data, please contact [email protected].”. This means that your request was detected as automated, and the rest of the result will be just an error page. To overcome this, try to change the values of your headers or add new ones and keep trying until you find the ones that work. If everything was configured correctly, you should see the whole page in HTML format in your Terminal.
At this point, you might be wondering how to understand the result. The data looks messy and confusing because it's hidden in complex HTML and is hard to read for a human. While you can find the information you need by putting in a little detective effort, scraping is only half the job of getting data from Amazon. Another part lies in parsing the data and making sense of the soup of text that you just received. You could even say you want to make your soup more beautiful.
Parsing the data
Beautiful Soup is a Python library that helps you parse scraped data to make it more human-readable. You can install it in the same way as you installed the requests library:
python -m pip install beautifulsoup4
While we won’t go in-depth about all the possibilities of this library, here’s how the previous code can be improved by simply picking out the elements you care about, in this case – the product title, price, and reviews:
import requests# Import Beautiful Soup so you can parse the results from the responsefrom bs4 import BeautifulSoupproxy_url = "http://{user}:{password}@{gateway}:{port}"proxies = {"http": proxy_url, "https": proxy_url}url = "https://www.amazon.com/Riwbox-TX8-Bluetooth-Headphones-Wireless/dp/B09FT3KWJZ/"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36","Accept-Encoding": "gzip, deflate","Accept": "text/html, application/xhtml+xml, application/xml;q=0.9,*/*;q=0.8","Content-Language": "en-GB","Upgrade-Insecure-Requests": "1",}response = requests.get(url, headers=headers, proxies=proxies)# Use Beautiful Soup to parse the HTML and present it in a more readable way. If you do a print(soup), you'll get a formatted HTML that is much easier on the eyes. You'll see a meowing duck, too.soup = BeautifulSoup(response.content, "html.parser")# Next, you want to pick out only specific elements from the response, in this case, the title, price, and reviews.# The title and price are fairly simple to get. Just inspect the page, find out the class where your information is stored, and run the soup.find() method to find the element.title = soup.find(class_="product-title-word-break")price = soup.find(class_="a-offscreen")# Reviews require a slightly different approach since several have more than one element to go through. Here, you'll get the review title, star rating, and the review text.# Use the soup.find_all() method to find items by classes and retrieve every element from a page corresponding to that class.reviewTitles = soup.find_all(class_="review-title-content")starRatings = soup.find_all(class_="review-rating")reviewTexts = soup.find_all(class_="review-text-content")# Finally, print the output. On the first line, print the product name and its price. Use the strip() to remove any unnecessary white space to make it look prettier.print(title.text.strip(), price.text.strip() + "\n")# For the rest of the output, use a for loop to go through each review 1-by-1. You can add some extra elements to make it easier to read, like in the example below.for (reviewTitle, starRating, reviewText) in zip(reviewTitles, starRatings, reviewTexts):print(reviewTitle.text.strip() + " | " + starRating.text.strip())print(reviewText.text.strip() + "\n")
When you run the script in the Terminal, it returns the title, price, and reviews as results. While it is far from perfect, it’s readable, valuable data! You can learn more about how to make the most out of Beautiful Soup by reading their documentation. It will help you customize the code to fit your needs, extract what you want from a web page, and present it cleanly and concisely, for example, in a CSV file.
Tips & tricks
Scraping data from Amazon doesn’t stop at knowing how to write web scraping code. To ensure a smooth and issue-free process, you must know how to avoid CAPTCHAs, IP bans, or other errors, which you can do by following these tips:
- Implement proxy rotation. You can configure your proxies to rotate every few requests in the code or use a rotating proxy type so that each request you make will come from a different IP address. It will make it harder to track where the requests are coming from and make you appear as different connections worldwide.
- Use real headers and rotate them. Headers are vital in making you look as authentic as possible. Make sure they are real and commonly used; for example, use popular browser names inside your user agent. Using uncommon settings like niche browsers or outdated operating systems might set off some red flags for Amazon, and you will likely appear suspicious. You should always have a list of user agents alongside several other types of headers and rotate them frequently.
- Use headless browsers. Don’t you want to write your own headers and worry whether they are authentic? Headless browsers such as Selenium do the job for you, as they simulate actual browser behavior. Just make sure to turn off bot indicators, as Selenium sends them by default, telling the website that the request comes from an automated process.
- Make your web scraper look like a real user. If you build a more complex web scraper that goes through several pages to scrape data, ensure it acts naturally as a real user would. The script needs to go from page to page through hyperlinks, interact with the first page and Amazon search page, check out a product, spend a little time reading about it, then go back, select another product, and so on.
- Monitor your scraping process. The product pages can change and provide different information or even have different page layouts the next time you open them. It means the previously working code will yield no results as it can no longer extract Amazon product data. Update your scripts and tools accordingly.
Wrapping up
Scraping Amazon data may seem daunting at first, but with a little effort, it’s a breeze to gather the information you need effectively. It’s a worthwhile investment for your eCommerce business as it provides incredible market insight that any successful business needs to grow. Together with Smartproxy’s datacenter proxies, this becomes even easier and unlocks the full potential of what you can do with your web scraping tools and scripts.
About the author
Martin Ganchev
VP Enterprise Partnerships
Martin, aka the driving force behind our business expansion, is extremely passionate about exploring fresh opportunities, fostering lasting relationships in the proxy market, and, of course, sharing his insights with you.
All information on Smartproxy Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may be linked therein.

.png?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max&rect=0%2C0%2C1024%2C576&w=1024&h=576)



