Table of content
Opening The Off-Limits Codeless Scraping World: How Did We Develop a No-Code Scraper
No-code scraping can be complex. I tested quite a few software for codeless scraping and noticed that the existing solutions could still be a struggle for non-coders. So, naturally, I felt encouraged to develop something different: Smartproxy No-Code Scraper. Yes, my idea wasn't unique, as it's a commonplace in the developers' world, but I knew I could simplify scraping.
So, I gathered our small team – a product designer, front-end and back-end developers, and me (a product owner) – who was willing to give no-code scraping a shot at seeing the light of day. The result – after five months of struggles, we released the tool that automatically scraped the selected data on a recurring basis. The development process wasn't as easy as expected. But let's start everything from the beginning.


- Smartproxy >
- Blog >
- Data Collection >
Opening The Off-Limits Codeless Scraping World: How Did We Develop a No-Code Scraper
Passion for no-code
In my previous blog post about the No-Code Scraper extension development process, I wrote about my no-code mania and a desire to open the scraping gates to everybody. Actually, the extension was just a part of a story; we started by building two versions of a no-code scraping tool: our premium dashboard with scraping templates and the free extension. The latter was launched without waiting for the real version of the product. In fact, we built both tools simultaneously; just the implementation of the No-Code Scraper took longer due to the development complexity. And I’m going to share all the scenes in this blog post.
Differences between the two versions of the product
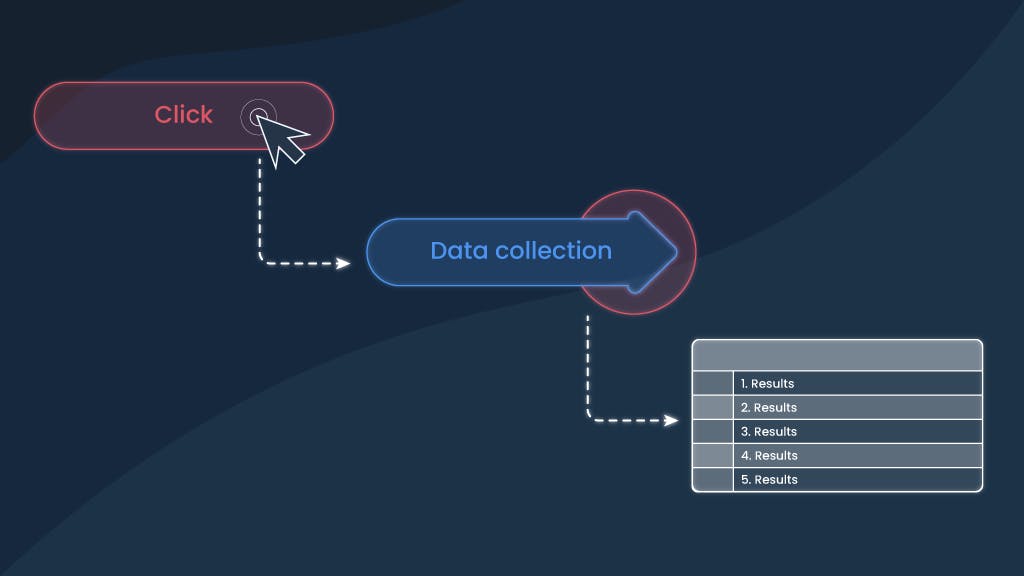
Let's have a quick overview of both tools. The extension is a handy tool that allows users to collect data points by clicking them on the website. Let’s say the user needs to scrape eBay product titles, prices, and the number of reviews. All it takes is to install our free No-Code Scraper extension, open the eBay page and click on those elements. Voilà – everything is put on the table in seconds, and the user can instantly download the data in JSON and CSV.
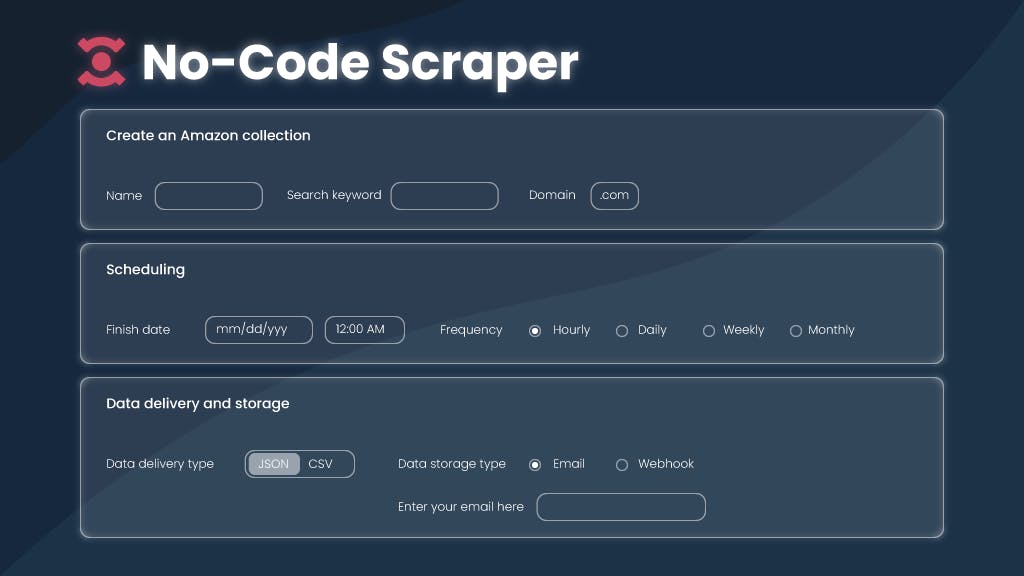
With our dashboard version of the No-Code Scraper, there’s even more fun. With it, the user can:
- Use premade Google and Amazon scraping templates or target almost any other site with a Universal template.
- Schedule data delivery. For example, get Amazon product data every Monday.
- Store the scraped data on our cloud instead of downloading everything.
- Get data delivered straight to email or Webhook.



Storage and delivery
While creating our premium version of No-Code Scraper, we spent a lot of time investigating what our users would be, how well they understand how data collection works, and what kind of facilities they have. When discussing a storage solution, we quickly agreed that we should take care of cloud solutions to avoid hassle or additional storage infrastructure costs for the user. So now, we keep the extracted data in one place from where the user can download it anytime.
For the delivery itself, we made a similar solution that could be convenient, let’s say, for a data analyst. We’ve chosen email – this channel works well as a notification informing that the data is ready for further analysis. We added the Webhook option, too, making the integration with third-party tools like Zapier or Make easier.
Making scraping easier with templates
Our team was building our no-code tools in parallel with the Smartproxy Scraping APIs, so naturally, we checked what technological aspects we could reuse from existing resources. First of all, we had a goal to open up codeless scraping for various niche targets. So, we built a Universal template using technology from Web Scraping API at its core.

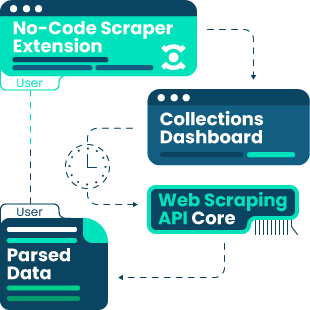
Aside from niche targets, we saw a need to base product or competitor research on data gathered from well-known search engines and eCommerce sites. Such data gathering is usually all-important for data analysts, side hustlers, etc. Those people do not necessarily have extensive coding and data collection knowledge. Following the market’s practice, we built predefined Google and Amazon search templates to make codeless scraping effortless.
Why only Google and Amazon?
Initially, we planned more targets, but due to the project’s scope, we decided to take off with the two main ones. Additionally, the Universal template enables users to scrape almost any other site either way.
More templates meant more time spent monitoring them because the target's structure can change at any time, making the old scraping logic non-functional. Since we couldn't dedicate so much of our resources to template management (as only four of us were working on this no-code product line), we chose to start with less and check whether we found a market fit. So, we invested in building the first sites people explore, for starters.
Ideas can be too big
As a real no-code fan, I initially wanted to build a powerful No-Code Scraper. Back then, it looked so real that our team could change the traditional scraping landscape by introducing easy-to-use solutions. But then reality kicked in.
We were willing to build not only a universal scraper for random websites but also a universal eCommerce scraper that can handle any such site automatically. But because of the complexity and development costs, we dropped the latter idea.
After digging more into details, we understood we could implement such a tool, but it'd be too complex for a user without coding knowledge. For us, simplicity was key, so we continued to work on that, leaving this idea for the future. There's always a trade-off.
Developing simple-looking features can be lemon difficult
Sometimes (or should I say most of the time), the development process takes longer than expected. In our no-code fever case, we started building the extension and the dashboard version simultaneously. The latter just took longer because it required back-end development while the extension was based only on the front end.
Besides, it involved more technical parts such as creating a new subscription type, taking care of cloud storing solutions, and data converting process to excel-like files. But all of this was a snap compared to scheduler building.
Struggles with scraping tasks’ scheduling


With our No-Code Scraper, users can schedule scraping tasks and receive the required data repeatedly (daily, weekly, or monthly) straight to their inbox. Scheduling was a must to prevent the repetitive data selection process. We wanted the user to refrain from bothering about data collection, installing additional programs, or creating flows to consistently get that data. It all sounds nice, but it took us almost five months to develop this scheduling technology. It's the main reason why we launched the extension without waiting for a dashboard version of the scraper. Crazy!
To build a scheduler, we needed to create a separate database that constantly checks when the scraped results should be sent. To make it deliver data smoothly, we had to set up multiple back-end services that would interact with each other and verify if all the data was scraped and ready to be delivered. Most importantly, we needed to ensure the results were error-free. It took us a while to make everything work as expected and enable the scheduler to send the scraped data via email.
Ensuring a seamless authentication process
There are different ways to use our No-Code Scraper. If the customer needs to scrape only Google and Amazon, one can schedule scrapping tasks without leaving our dashboard. The extension is necessary only when the users scrape other sites and build collections with the Universal template. It's necessary because every site is different, and the user needs to select the data points manually for the first time.
So, where's the problem? From the user side, jumping from the extension to the dashboard seems intuitive, but it took us a while to ensure a smooth authentication process. We needed to make everything look natural without requesting the user to log in again and again. To make it genuinely instinctive, we built a flow to pass authentication details via the request header straight to the dashboard. It ensures the user automatically logs in, creating a seamless transition between the dashboard and the no-code scraper extension.
Selectors' journey between the tools
Another challenge was to ensure that we can transport the selected elements from the extension to the dash without screwing something up. We had some “fun” ensuring that each selector represents a precise path of the data point location by disclosing its parent element in the <div> structure. It was vital for delivering accurate information.

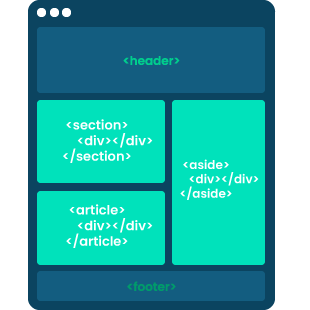
A glance at the final scraping process
I described tiny parts of the struggles we have faced. Now let’s give a short overview of the final scraping process.
All the magic begins when the user creates a collection on our dashboard. Then our No-Code Scraper reaches the target using proxies from our 65M+ pool, automatically assigns fingerprint details, such as user-agents, extracts the HTML, and picks the elements user has chosen using XPATH selectors.
The selectors replace the developer’s work by identifying the requested elements and parsing them in JSON. If the user’s selected format is CSV, we convert the data from JSON and return it via email. Or the users can download the scraped results directly from the dashboard.
Advice for users
Yup, some issues can still occur while using our tool, but I have some tips on how to have a smooth no-code scraping experience:
- Select data that is publicly available. I’m not talking here about scraping for shady needs (Smartproxy doesn’t allow it by any means!); some issues can occur while scraping, from the first glance, public data. If you’ve selected data that is not accessible (protected by logins, dropdowns, etc.), No-Code Scraper selectors probably wouldn’t find and parse it.
- Check if the created collection is correct. If data is received in a different format than requested, try remaking the collection either via the dashboard (for Google and Amazon targets) or via the extension (for a Universal template). If everything is okay from your side, contact our support, and my team will check what caused your struggles.
- Choose the correct email for delivery. The email world is a mystery; therefore, if you don’t get your data to your inbox, check if it’s not full or if the address didn’t end up on the block list. If it doesn’t work, try another email address you’d prefer to get the scraped data to.
Endless amount of ideas for improvement
As one of the owners of the tool I have many plans on how we can add extra features to the existing version of the No-Code Scraper. Starting from new integrations, more templates, and scheduling options (now the user can receive data after one hour), finishing with UX improvements.
By the way, if you’re up to try this No-Code Scraper tool, grab our month-long free trial. Just sign up on our dash, and you’re free to go.



Paulius Taraškevičius
R&D manager
Meet Paulius – he builds tech stuff and makes his ideas contagious. Be aware – you might catch a no-code fever or a desire to start side-hustling just by staying too close next to him. Please don't say we haven't warned you later…
Frequently asked questions
What is the difference between no-code and low-code scrapers?
No-code scrapers are designed to be user-friendly and require no coding skills. They usually have a graphical user interface (GUI) that allows users to select the website they want to scrape and the data they want to extract. No-code scrapers are perfect for people who want to quickly extract data without writing any code.
Low-code scrapers, on the other hand, are for users who want more control over the scraping process. These tools often have a GUI for selecting websites and data but also allow users to customize the scraper's behavior using code snippets or pre-built templates. Low-code scrapers are a good option for users with some coding experience who want to fine-tune the tool to meet their needs.
Can you scrape data with Smartproxy’s No-Code Scraper from any website?
Yes, you can scrape different websites using a Universal template. It lets you choose the specific parts of the site you want to collect and get the data whenever you want. Of course, every website is different, so if you hit a snag, just give us a shout on our 24/7 LiveChat, and we'll be happy to help you out ASAP.
Why is no-code better than coding?
No-code scraping tools are the perfect solution if you need to collect data from websites but don't have programming knowledge. They're easy to use, with intuitive click-and-collect interfaces that make the process simpler and more user-friendly. Plus, you don't have to spend time writing and debugging code, which can save you a lot of time and money.
However, it's worth noting that no-code tools may not be as customizable or powerful as traditional scraping methods and may not be suitable for more complex projects. It's important to consider your specific needs and skill set before deciding which option to choose.
The good news is that with Smartproxy, you have options. You can try our No-Code Scraper, which is designed to make web data collection a breeze. Or, if you need more power and flexibility, you can use the four APIs in our scraping line designed for eCommerce, SERP, web, and social media data collection. Whatever your needs, we have a solution that will work for you.
Why do you need proxies for scraping?
There’re quite a few reasons for that:
- Avoid getting blocked. When you scrape a site, you're sending a lot of requests from the same IP address, and such behavior can earn you a CAPTCHA. But with proxies, you can use different IP addresses for each request, making it harder for the website to detect and block your scraping activities.
- Bypass geo-restrictions. Some sites limit access to their content based on your locations; gladly, you can unlock the most localized data with our residential proxies located in 195+ locations, including cities and US states.
- Scrape anonymously. By routing scraping requests via the proxy server, you hide your real IP address and keep your identity unrevealed.