

Table of content
How Hundreds of Failed Tests Led Us to Create a Functional Extension Everyone Can Use
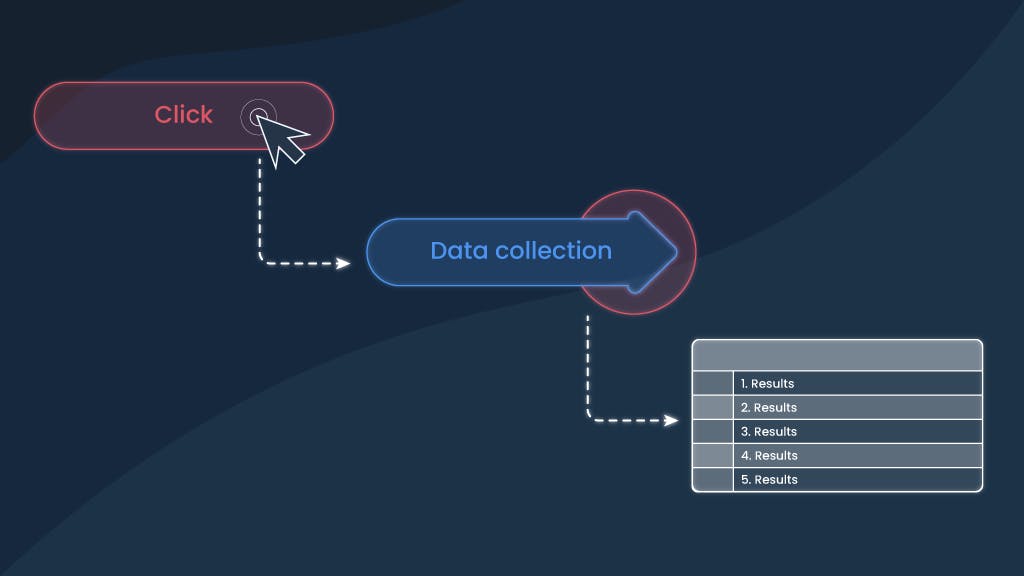
Is it possible to have the powers of a developer without being one? Can a person without any coding knowledge scrape something? These were the questions that I kept asking myself while chasing new side-hustle ideas. One day, I decided to find an answer myself and build a tool that forms data lists without writing a single line of code. It was challenging, but I convinced my talented colleagues that this idea had great potential and that we were ready to make it happen.
Couple of months later, the launch day comes. After a (not so) dramatic countdown, our No-Code Scraper extension is live. Our two months' work turned into a tool ready to enable people to scrape visually. That's right – to collect data just by pressing on the necessary stuff without a need to code or have data engineering knowledge. How have we managed to do that? By experiencing struggles, unsuccessful tests, and sometimes – unsweet back-and-forth processes. Here’s how it started.


- Smartproxy >
- Blog >
- Data Collection >
How Hundreds of Failed Tests Led Us to Create a Functional Extension Everyone Can Use
No-code mania
We all know at least one guy who is so much into something that he starts to annoy friends by constantly talking about his passion. In this story, it was me – I was constantly thinking about and testing no-code tools. At work, together with a team, we were building three Smartproxy’s Scraping API lines, while at home, I was building MVP websites for my side hustles using Bubble, Backendless, and other no-code tools. And these circumstances caused a perfect click – I was stoked about both things when I started questioning myself: should we build our own no-code tool for scraping?
I was excited about building a tool for people like me, for those with many ideas to test and validate. Or those who are already passionate about no-code and want to try something new. Or the solopreneurs, spending their spare minutes on indiehackers.com looking for the best way to skyrocket their projects.
… but do we really need another tool?
So, no doubt, I needed to prove to my team that a codeless scraping tool is something our users would like to have. I convinced our talented product designer and front-end developer to join this no-code journey, and we started digging deeper into the no-code market and the solutions offered by our competitors.
For the record, our research started after the Covid-19 outbreak, when due to flexible schedules, many people had more time to test new ideas. We noticed more active solopreneurs and side hustlers. That meant more people needed to test and validate their ideas and didn't necessarily have enough data for this or extensive computer programming knowledge to scrape it. Consequently, I noticed a lot of scraping-related tools on producthunt.com getting popular. The demand for such solutions was pandemic-immune – people wanted to gather data hassle-free for their projects. Seeing those tendencies, we had only one question – now or never. So, we chose ‘now’.



Asking the customers
We weren’t pioneers. Our competitors already had some tremendous no-code tools for data gathering. But the more we dug into competitor research, the juicier it got. We found quite a few great tools, but they were pretty complex. Two reasons why: 1) they were designed only to scrape specific targets, like Google or Amazon; 2) the request formulation process required providing too much information that the user doesn’t necessarily know. In other words, the existing codeless scrapers weren't an option for those who don’t know how the scraping process works. What’s more, later, when talking with customers, I discovered that people need to scrape various pages, not only the most popular search engines or eCommerce targets.
One of the most exciting interviews I had was with a mapping company that was building a global transport platform. They aimed to place interactive public transport and taxi maps into one platform. Back then, they had enough data analysts but not enough data engineers to take care of scraping and parsing. So, their pain point was to have a tool that would enable teams with fewer data specialists to perform scraping, parsing, and general data collection processes smoothly.

Is there a simple solution?
Our competitors had (and still have) great tools backed with various scraping templates and APIs. The problem I noticed was the complexity of requesting data. The user had to select many filters related to data formats, parsing methods, proxies, etc. All this makes sense, but usually, the hustlers in the early stage of the project don't know whether they should choose CSS or XPATH, what kind of proxies or digital fingerprints they need, or where the scraped data should be delivered. Instead, they need a simple tool that can take care of all scraping nuances. It was our chance to enter the growing market and create a low-complexity tool.
What does simplicity look like?
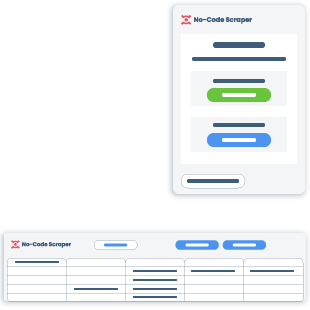
We started researching how such a tool should look like. The extension seemed like the simplest form of the product everybody is familiar with, so we agreed that this is the format we would stick to for starters. We wanted to create an extension that could scrape data points by simply pressing them on the website. Simplifying a complex process involving many details sounded demanding, yet positively challenging (or perfect enough) for crazy people like my team and me.
We were about to create a tool that doesn't require users to describe the data they need. Instead, the extension should understand if the necessary data point is a link or image and return the selected results in a well-known format. So, our goal was to develop a functional tool that could complete the scraping process without too much user involvement. Little did we know that making something look simple is actually difficult…

Visual representation
Before building our product, we needed to understand how to represent the scraped results. It was a question of how to win the “aha!” moment when the user selects the data points and initially gets the result displayed on the screen. We tried pop-ups, side/top/bottom bars, and whatnot during our tests. While solving this issue, we faced a tricky question – how not to change the content structure displayed for the user? Yup, that was a real problem. ‘Till we found a solution, the toolbar used to mess up the view of the page (it can happen since the extension uses Google content scripts). The best option we tested was to put the bottom toolbar on the surface of the page without changing something from the responsive side.
But the challenge wasn’t over since we kept adding some functionalities or design solutions. Sometimes, our attempts even caused changes in the target pages; for example, opening a web for the user in different colors than the original. This ‘don’t break the page’ game was a real pain in the ass (but a funny one) we had to deal with while building the extension.
The best way to show results that we found was the table – each column dedicated to a different chosen value. Having tried many no-code tools, I noticed that the immediate result is a thing the user is getting used to. And the simple table looked like the best solution.
Stuck on JavaScript libraries
Our plan was to build the extension functioning on the click-and-collect principle on different websites. The problem is that many websites aren’t based on the static HTML code structure, and we needed a tool that can deal with different targets. So, we chose to write a selector using JavaScript. All the process looked like this: the user selects the HTML element, and from it, we take the selector and tweak it to recognize other matching elements. After finding all of them, we put the results into the table.
To make this process as smooth as possible, we tested various JavaScript libraries. And, oh my, finding the one suiting our idea took a lot of work. We kept trying new codes, then building features on top, editing them, and starting all over. It already had been going longer than expected.
Dealing with <div> infinity

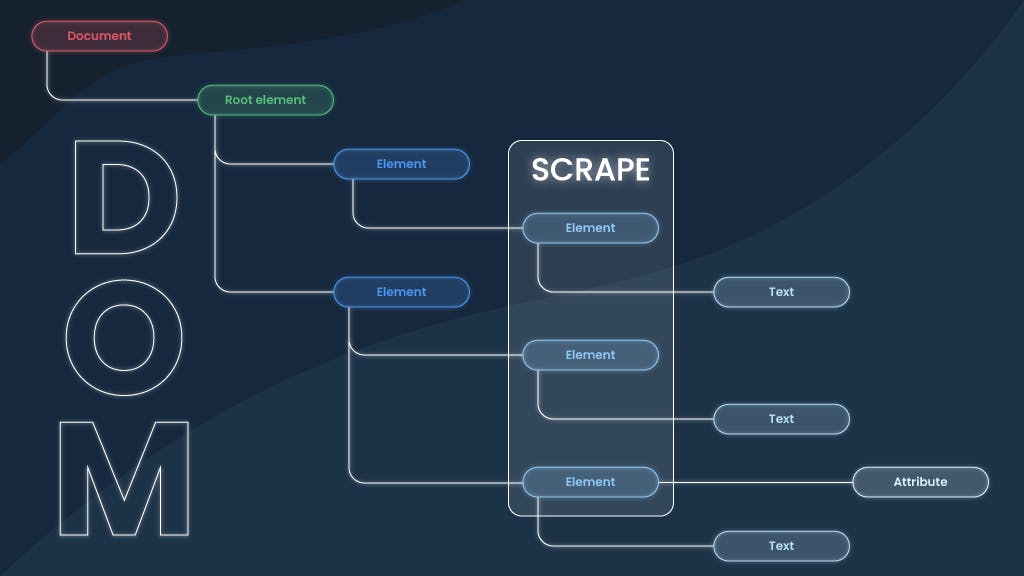
The biggest fear while building such a product is not the error itself. It’s an error you cannot explain. Some screw-ups occurred when the tool failed to deliver the selected data points and presented empty columns. Such things happened (and still sometimes happen) because some sites have unique layers or, let’s say, protectors that prevent visual scraping. Websites are based on Document Object Model (DOM) structure, where each data object, called <div>, stands hierarchically under other data points in the HTML code. From the user side, it looks like you did everything correctly, but the result is an empty column caused by an additional layer the element is placed under.
Could empty columns be a solution?
There's another reason empty columns were expected guests during our tests. Some selected items just don’t contain the same amount of elements. You can quickly notice that while scraping Amazon products. For example, some products have a discount price, and some don’t. It was a struggle to make the tool ‘understand’ which element should be left empty without assigning the discount price to another product. We solved this issue by leaving the empty column near the original price for the discount.
Not all issues are meant to be solved
However, not all the problems can be solved – websites are built following different logic, and we cannot predict all possible scenarios. Updating the extension’s selector for billions of websites out there would be mission impossible, so we added a “Report this URL” button to gather feedback about the failing sites. After optimizing the most popular targets, we even developed scraping templates for Google and Amazon, available on our premium No-Code Scraper, but that’s another story.
Our extension has some limits. After many tests, we noticed that pagination and infinite scrolling will be a problem. Simply because the extension can scrape only the information from the frontend even though results are loaded on the backend. Solving these issues would mean overcomplicating the extension, so we took that trade-off for the sake of simplicity.
Releasing MVP
Before the launch, we asked some Smartproxy customers to test the extension – we were curious whether this solution was straightforward enough. The heat maps showed there was still room for improvement.
Our initial idea was to run the script to find all the matching selectors after the customer selects at least two elements, but it wasn't intuitive from a user's side. We improved that, and in the current version, users can scrape a list by selecting only one element. Despite that, 89% of test participants agreed that such a tool could solve their existing data scraping problems, so we knew we were on the right path.
The final result
After running many tests, going through headaches while choosing between JavaScript libraries, mastering <div> unlocking game, and trying to implement simple data representation, we were done. No, really. We launched the No-Code Scraper extension you can download for free on the Chrome store! We were a bit late, but happy with what we got. We build a tool that can deliver user image URLs, tags, names, links, and many more things just in a few clicks. Easy as that.
How can you use this extension? Here are some ideas you can try:
- Extract statistical metrics by scraping big data from various sites;
- Download competitor product names, prices, and descriptions;
- Generate leads by building contact lists with publicly available data;
- Protect your brand reputation by gathering reviews and media mentions in one place.
I surely can provide more examples, but I guess you’ve got an idea.
The story behind the name
“No-Code Scraper extension” wasn’t the first name we called our tool. Since we are Smartproxy and we have smart solutions, we named our tool “Smart Scraper extension” because it was smart (ba dum tss). Ease-of-use, various data point selections, and fast result delivery seemed like a fair reason for that name. After launching our premium software version, we renamed both tools emphasizing the no-code function just to avoid more confusion. We loved our old name, but we took off that “Smart” T-shirt to give more clarity for the users.


What’s next?
We’re probably developing something new, like the dashboard version of the No-Code Scraper, while you’re reading this, so one thing is clear – you cannot be sure what we will come up with next. So, stay tuned. I guess.



Paulius Taraškevičius
R&D manager
Meet Paulius – he builds tech stuff and makes his ideas contagious. Be aware – you might catch a no-code fever or a desire to start side-hustling just by staying too close next to him. Please don't say we haven't warned you later…
Frequently asked questions
What is the click-and-collect principle of the No-Code Scraper extension?
Click-and-collect is a way to gather information from a website using the No-Code Scraper extension. It allows the user to click on specific data points, according to which the extension automatically scrapes all the matching elements on the same page and puts them on a table.
Suppose you want to compile a list of the best-selling books on Amazon. You can visit the Amazon website and activate our extension. Once you click the "Free scraping" button, you can select the relevant data points such as book titles, authors, and prices. The extension will automatically add the selected data to your list with each click. You can then download the list in JSON or CSV format.
What is a scraping template?
A scraping template is a pre-defined reusable set of instructions used to extract data from websites. It's like a recipe that tells you how to find and gather specific information from a web page. Scraping templates are handy for automating data collection, making it faster and easier.
For example, if you wanted to scrape product data from Amazon with our No-Code Scraper, a scraping template would help you to collect the data according to your provided keyword and selected domain. You can choose the delivery frequency, format, and storage type and get the data when needed!
What is an MVP?
Minimum Viable Product (MVP) is the first version of your web product that you can launch to the world. It has just the right amount of core features to get the job done, so MVP is a solid foundation to which you can later add more features.
Is the No-Code Scraper extension only available on Chrome?
Yup, our free extension version is currently only available on Google Chrome.
What is the difference between scraping and parsing?
Scraping and parsing are two terms related to data collection. Web scraping is a process of data extraction from a target website. Data parsing is a subsequent activity of structuring and converting extracted data to a specific format.
Scraping a website involves extracting the desired information from its HTML code. Usually, it's done with data collection automation tools. On the other hand, Parsing involves analyzing the scraped data by breaking it into its individual components, making it easier to study.






