

How to Scrape Google Search Data
It’s hard to imagine a successful business that doesn’t gather or use any form of data in 2023. And, when it comes to data sources, Google search engine result pages are a goldmine.
But gathering Google search results isn’t that simple – you’ll encounter technical challenges and hurdles along the way. Luckily, some powerful tools and methods can automate search result extraction.
Fret not – we’ll review different methods to scrape Google search results, discuss why it’s worth doing and show you how to solve any possible issues you might encounter while scraping Google SERP data. Shall we begin?



James Keenan
Feb 20, 2023
8 min. read



What are Google SERPs?
Before we get into the nitty-gritty of Google web scraping, let’s find out what Google SERPs are.
SERP is an abbreviation for Search Engine Result Page. It’s the page you get when you type in “egg boiling time” or anything else into the search box of the engine.
The interface of a Google SERP has changed a lot throughout the years – what used to be just a simple list of search results is now way more complex. Today, Google has a number of different SERP features (also known as Rich Snippets), such as Knowledge Graphs, People Also Ask boxes, reviews, News boxes, and others. So, when it comes to choosing a solution for scraping Google, you should go with the one that can also scrape rich snippets.
Why businesses gather data from Google: everyday use cases
Google currently holds 84% of the global market share of search engines, as measured by Statista. The second-largest search engine Bing has a little over 8% market share. Google is also (by far) the most visited website in the world.
These statistics tell us that no matter the industry you operate in as a business, your customers and competitors are likely to be on Google. So, it’s like a treasure chest, holding a massive potential for your business growth. Below are some common scenarios, along with their business personas.
Which elements of a Google SERP are scrapable
Before learning how to scrape Google, it’s crucial to understand how it shows your searches. And the display of search results has changed a lot! The days when you saw only an index of pages with URLs, the so-called organic search, are done.
Although the primary purpose of Google is to enable you to answer your queries quickly and efficiently, it’s not just that. To make you choose Google over others, it also seeks to display your search results in a way that’ll be attractive and easy on the eyes.
That’s why the display of search results has changed significantly over time. Depending on the complexity and type of search, you’ll see different content on Google. As an illustration, type “data collection” and see which components make up a Google SERP. Below you’ll see what pops up in our browser.
Everything depends on the keyword that you’re googling. Here’re all the elements that might appear on Google and can be easily scraped with our SERP Scraping API:
- Paid and organic search
- Travel industry
- Popular products & listings
- Videos
- Ads (real-time)
- Images
- Google Shopping
- Related questions
- Related searches
- Featured snippets
- Local pack
- Top stories
- Hotel availability
- Restaurant data
- Recipes
- Jobs
- Knowledge panel
If you're interested in identifying the SERP features associated with your selected keywords, the SE Ranking rank tracker is a useful tool that allows monitoring more than 35 different SERP features.
How to scrape Google search results
When discussing Google search data scraping, a question often arises – does Google offer an official solution for its data acquisition? And the answer is… (drum roll) – no. Unfortunately, Google doesn’t provide an official API for scraping, making it challenging to acquire its data at scale.
Of course, there’s always the option to gather data manually, but this method has two issues. When collecting data manually, you should arm yourself with patience as it’ll take hours of your time, and in the end, you might not get accurate results.
Hence, you’ve got roughly three ways to acquire Google search data: semi-automated, automated (done yourself), and automated using time-saving tools (cough*Smartproxy*cough).
Option 1: Semi-automated data gathering
Building a scraper requires some coding knowledge and other technical steps (as we’ll see further below). However, depending on the type and amount of data you need, you might be able to use a semi-automated method instead.
A quick and easy solution is to build a (very) basic scraper in Google Sheets. For this option, you don’t need to write any code. Only a Google Sheet and a few special formulas are needed. This solution is helpful when you wanna collect basic information from a list of web pages.
Say you need some basic Google search results (like meta title, meta description, or author’s name) from pages that compete with your own page on Google for a certain keyword.
You can use a custom version of Google Sheets’ IMPORTXML function with an additional argument (called “xpath-query”) to automatically import the data directly from the web page’s HTML into your spreadsheet. This formula searches through the page’s HTML to retrieve the element that you wanna it to look for, such as <meta name=” description” content=”...”> for page’s meta description.
Technical difficulties of this method:
- Having to do some work manually. For basic queries and small-scale Google SERP data gathering, this method can be pretty useful. However, you’ll still need to do the setup manually.
- Limited amount of data. This method is great if you wanna extract some basic information; however, if you need large volumes of data, we’d suggest going with the methods described below.
Option 2: Automated data gathering by building your own scraper
The next option opens a lot of possibilities as it allows you to scrape Google SERP data in an automated way.
A web scraper is a robot you can program to automatically retrieve vast amounts of data. This robot crawls a URL (or set of URLs) by visiting them, going through all the data on a page, and extracting the data to store it in a database.
The scraper can continue crawling through new pages by following hyperlinks, thus enabling you to gather data from thousands of web pages at once. Following this method, you wouldn’t need to manually feed your robot every page you wanna crawl.
If you wanna scrape Google search results for a specific query, you can create a Google result scraper that you only have to feed the Google Search query of choice, and the scraper will do the rest for you.
But you should know one important thing – websites don’t like scrapers visits. When the anti-bot system detects that your IP address is tied to the scraper, you might be awarded an IP ban. That’s where proxies come in handy. They rotate your IP address and trick the websites into thinking that the robot is a genuine visitor. And it happens that we have a list of scraping-designed proxies with a massive pool of 65M+ residential, mobile, and datacenter IPs. Give our twice as fast as the SEO proxy industry average proxies a try with a 14-day money-back option (terms apply)the !
Building a custom, in-house scraper definitely has its perks: for starters, you can build it however you like! You’re fully in control of the development process, so you can ensure the scraper has features you truly need.
But, there are a few drawbacks here:
- User-Agent testing. Google tries to distinguish humans from robots by checking the User-Agent of the site visitor. To solve this problem, create a list of User-Agent strings used by real browsers and add this to a Python list.
- Request rate limitation. Google limits the number of requests a user can place within a certain timeframe. To avoid this, set specific time frames between requests and rotating proxies to change your IP.
- Robotic behavior. Google analyzes user behavior to predict whether the site visitor is a robot or a human. The solution would be to make the bot as human-like as possible.
- Blocklisted IP address. Once Google notices robotic behavior, it will blocklist it. To avoid this, rotate proxies and use high-quality IP addresses. The best types are unshared, residential IP addresses like the ones we offer – with an amazing 99.99% uptime and high success rate for Google scraping targets.
- CAPTCHA test. If Google suspects it’s dealing with a robot, it may request proof of humanity – you’ll have to solve a CAPTCHA test. Marking those bikes or putting a puzzle together could be difficult for robots, so you should try avoiding them by combining the above-mentioned methods.
Option 3: Automated data gathering using Smartproxy SERP Scraping API
The third option is to choose SERP Scraping API to do the work for you. Although thousands of different tools for scraping Google are available, each created to fit a specific purpose, Smartproxy wins for the range of handy features that this API is equipped with. Scrapingdog also provides an efficient solution for scraping if this is what you're looking for.
The most common web scraping tools are SEO tools designed for tracking the performance of pages in Google’s SERPs. They collect all sorts of page data, from average rankings to the number of words on a page or the number of backlinks a website receives from others.
Aside from these SEO-related scrapers, there are tools to gather all sorts of Google search results. You can find scrapers to gather data from Google Shopping results, Google Images, and Google Hotels.
Many SEO specialists choose SERP APIs for thorough keyword research. For instance, our Google Search API is a tool designed to extract data from different search types, so you are all set on reaching that sweet #1 spot on the SERP without breaking a sweat.
Technical difficulties:
- Requires initial investment.
- Need proxies to achieve the highest success rate.
- Might require technical knowledge to get the scraper up and running.
How to scrape using Smartproxy SERP Scraping API
Yes, it might require some technical knowledge, and if you’re doin’ it for the first time, it might be a lil’ challenge for you. But trust us, once you master it, you’ll be scraping those precious Google pages in seconds.
Step 1
Create your account to access our dashboard.

Step 2
Once you’ve signed up, wait for a verification email to arrive in your inbox. When you receive it, click the link to confirm your email address, and hooray! You can now explore our dashboard!
Step 3
In the menu on your left, select “SERP” (under the “Scraping APIs” section) and then “Pricing”. Over there, pick the plan that suits your needs best:

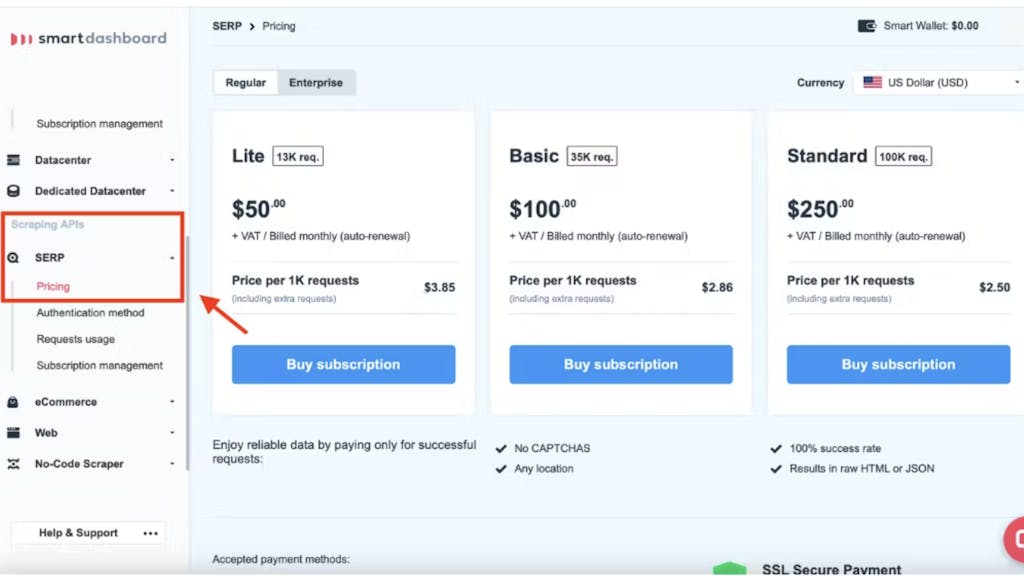
With Smartproxy, you never have to worry about yo’ payment. All our monthly subscription plans are recurrent. We charge you automatically, so you don’t have to manage anything. Of course, you can cancel, upgrade, or downgrade your subscription.
The cherry on the cake is that if you’re not satisfied with our SERP API, we’ll refund you! We offer a 14-day money-back option for all purchases on our website (terms apply).
Step 4
That’s where some coding comes into place. There, there… we told you, it’s easier than it sounds.
Let’s look at the code you’d need to write in a Python interpreter. Why Python? Well, it’s widely known for its simple syntax, so a lot of programmers opt for it. However, if Python isn’t your type, you can also use other programming languages or simply write a code in the Terminal (Mac or Linux users) or the Command Prompt (Windows fans). Keep in mind, though, that you’ll need different code then – for more info on that, look at our API documentation.
Below is a code for Python:
import requestsurl = “https://scrape.smartproxy.com/v1/tasks”payload = {“target”: “google_search”,“query”: “proxy faq”,“parse”: True,“locale”: “en-GB”,“google_results_language”: “en”,“geo”: “London,England,United Kingdom”}headers = { "Authorization": "Basic cHJdeHl3YXv6U1Bwcm94rXdhtTE=",“Accept”: “application/json”,“Content-Type”: “application/json”}response = requests.request(“POST”, url, json=payload, headers=headers)print(response.text)
Here, your URL would always be the same – https://scrape.smartproxy.com/v1/tasks. Don’t make any changes here. Just copy and paste. Period.
If you wanna scrape organic search results on Google, write “google_search” in the target line. As we said before, a Google search page is multifaceted, so many targets are available. If you’re after hotel deals on Google, write “google_hotels”. If you’re into book results, hit “google_books”. A list of all supported targets for our proxies is available in our documentation.
The query parameter indicates what you’d write in the Google search bar. In this case – “proxy faq”. Moving on, if you write “True” when specifying the parsing method, it means that your results will be parsed in JSON. Leave blank for HTML.
The locale parameter enables you to change the interface language of a Google search page (not the results). On the other hand, the results language parameter selects which language you’d like to get your results from Google. Access a complete list of available languages. The geo variable pinpoints which region you wanna target.
Regarding the remaining part of the code above (from headers), you should copy-paste it. Sure, another type of integration might require some minor changes. Yet, in general, the idea will be the same.
Step 5
The code above will return a huge set of beautifully parsed data. But what to do if you don’t wanna see all the results but only some specific ones? Depending on what you wanna filter, add these three simple lines in your Python interpreter:
my_list = parsed[“results”][0][“content”][“results”][“organic”]for k in my_list:print(k[“pos”], k[“url”])
We narrowed down the results so that only the URLs from the organic search of the keyphrase “proxies faq” would be visible. The code also extracts the position which a particular URL holds on Google.
Spot that tiny “0” in the code. It shows that we didn’t specify how many URLs we wish to get. In such a case, you’ll get ten results by default. Of course, don’t be shy to write a bigger number if you need more results.
So, those three added lines will return the parsed data below, including the position (from 1 to 10) for each URL:
1 http://www.freeproxy.ru/en/free_proxy/faq/index.htm2 https://brightdata.com/blog/proxy-101/common-proxy-questions3 https://wonderproxy.com/faq4 https://smartproxy.com/faq5 https://www.tue.nl/en/our-university/library/practical-information/faq/faq-proxy-server/6 https://desk.zoho.com/portal/iplayerproxy4u/en/kb/articles/proxy-faq7 https://limeproxies.netlify.app/blog/top-10-proxy-faqs-smarter-proxy-analysis8 https://duo.com/docs/authproxy-faq9 https://uncw.edu/reg/students-proxyfaq.html10 https://geekflare.com/best-proxy-browsers/
Scraping Methods Summarized
Now that you know more about how you can gather Google search data, it’s time to decide which solution best fits your needs. Going through the pros and cons listed above, you probably already have a favorite option in mind, but let’s quickly recap your possibilities:


Wrapping Up
In the end, the best solution for acquiring data from Google depends on your business needs, personal knowledge, and budget. Building your scraper can be a fantastic, flexible, and cost-effective solution if you're comfortable coding and have spare time on your hands.
However, you will be better off using SERP Scraping API in most cases. It saves you a lot of programming time and effort, and unless you’re a true coding expert, it’ll help you gather a lot more data than doing it yourself. SERP Scraping API provides accurate, real-time data from all Google features and products.
That said, choosing such a tool is the easiest way to scrape Google SERPs on a large scale. So go ahead and try out our SERP Scraping API with a three-day money-back guarantee!
This article was originally published by Sydney Vallée on the SERPMaster blog.
About the author
James Keenan
Senior content writer
The automation and anonymity evangelist at Smartproxy. He believes in data freedom and everyone’s right to become a self-starter. James is here to share knowledge and help you succeed with residential proxies.
All information on Smartproxy Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may be linked therein.



