Node Unblocker: A Comprehensive Guide
Imagine this scenario: you’re bored at work with nothing to do. You decide to check out Reddit for a few minutes, but oh no, your network admin has blocked the website! Restrictions like that can be very annoying. Thankfully, Node Unblocker is an easy solution to overcoming any imposed limitations.


%20(1).png?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max&rect=0%2C0%2C2000%2C2000&w=95&h=95)
Martin Ganchev
Apr 26, 2024
8 min. read



TL;DR
- Node Unblocker is a proxy application that allows you to bypass network restrictions;
- You can set up a local instance of Node Unblocker or host it as a web service;
- Node Unblocker doesn’t hide your IP address from the target website but hides your activity from your network administrator;
- You can set up Node Unblocker with Puppeteer for automated scraping tasks;
- Node Unblocker can assist with various use cases, such as market research, analysis, content aggregation, and eCommerce trends.
What is Node Unblocker?
Node Unblocker is a web proxy service that allows you to access blocked websites by rerouting internet traffic through its servers. When you access a website through the application, it fetches the requested content and passes it back to you. This can help bypass internet censorship in a country or restrictions imposed by your workplace or educational institution. Node Unblocker essentially acts as an intermediary between the user and the blocked website, enabling access to content that would otherwise be inaccessible.
Unlike a typical proxy service, Node Unblocker doesn’t hide your IP address from the website you’re trying to access. It’s simply a convenient tool to bypass restrictions imposed by your network administrators limiting or blocking your access to specific websites.
To gain complete anonymity when browsing the web, consider using proxy providers such as Smartproxy. You can integrate these proxies in any application or script and make requests using 65M+ IPs worldwide, hiding your internet activity from your network providers and the websites you’re accessing.
How to use Node Unblocker?
To start with Node Unblocker, you’ll need to set up some things first. The initial preparation might take a few steps, but the tool becomes easy to use later. Read on to learn how to get everything up and running.
Install Node.js
Node Unblocker is written in JavaScript and is based on the Node.js runtime environment. To start with Node.js, go to the official website and download the latest version. Then, follow the installation wizard to set it up.
Create a new Node.js project
Once you have Node.js installed, open your terminal tool and use the cd command to navigate to the directory where you want to create a new project.
cd path/to/your/project
Run the following command to initialize the project:
npm init -y
This will create a new package.json file where you can define your project parameters.
Install required packages
You’ll need to install two packages – Express.js and Node Unblocker itself. Express.js is a web application framework for Node.js, designed to simplify the process of building web applications and APIs. You can install both with one command:
npm i express unblocker
After a short installation, you’ll see a new node_modules folder inside your project directory containing the express and unblocker modules.
Create the Node Unblocker script
In the root directory of your project, create a new index.js file and open it.
Start writing the script by importing the required libraries:
var express = require('express')var Unblocker = require('unblocker');
Then, create new express and unblocker instances. You can also define the prefix you want to use in your URL for the new unblocker instance. Name it anything you want, but we’ll stick to a good old '/proxy/' for this example.
var app = express();var unblocker = new Unblocker({prefix: '/proxy/'});
The next line tells the Express application (app) to use the middleware function unblocker to handle incoming HTTP requests:
app.use(unblocker);
Define a route for handling HTTP GET requests to the root URL ('/'). When you send a GET request, Express will execute the callback function provided as the second argument. Inside the callback function, req represents the HTTP request object, and res represents the HTTP response object. The function typically contains logic to process the incoming request and send an appropriate response, but let’s leave it blank (default) for now.
app.get('/', function(req, res) {});
Finally, start the Express application and tell it to listen for HTTP requests on port 8080 (or another port of your choice). We also attach an event listener to the server instance to watch for WebSocket upgrades.
app.listen(process.env.PORT || 8080).on('upgrade', unblocker.onUpgrade);
Here’s what the full script looks like:
// Import required librariesvar express = require('express')var Unblocker = require('unblocker');// Create new express and unblocker instances. Set a prefix to use in the URLvar app = express();var unblocker = new Unblocker({prefix: '/proxy/'});// Tell the Express application to use the Unblocker middleware to handle HTTP requestsapp.use(unblocker);// Define a route to handle HTTP GET requestsapp.get('/', function(req, res) {});// Start the express application on port 8080app.listen(process.env.PORT || 8080).on('upgrade', unblocker.onUpgrade);
Run the Node Unblocker
Now that the script is ready let’s get it up and running. To run the script, simply execute the following command in the terminal:
node index.js
A new instance of Node Unblocker will be started locally. Open any browser of your choice and enter the URL you’re trying to access in this format:
localhost:[port]/[prefix]/https://example.com/
Using our example, let’s access the Smartproxy website. Your URL, in this case, will look like this:
http://localhost:8080/proxy/https://smartproxy.com/
Just like that, you’ve accessed a website using Node Unblocker.
How do you use Node Unblocker for web scraping?
You’ll need a browser automation library such as Puppeteer or Playwright to use Node Unblocker for web scraping. You’ll also need to host your project online as a web service, as these libraries cannot interact with local testing environments.
Set up your project online
Choose a cloud hosting service like Amazon Web Services, Google, or Render. For this example, we’ll be using Render. If you choose a different service, follow its documentation to set up, upload, and host your application.
Create an account or log in to the Render dashboard. Then, click New and choose Web Service.


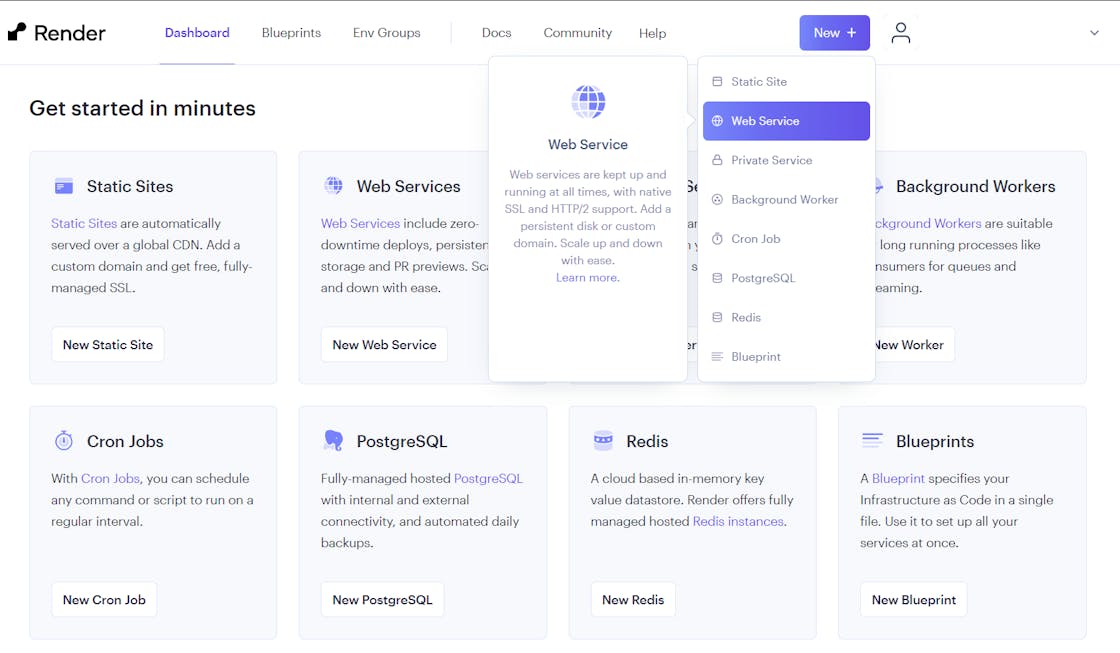
In the next step, select Build and deploy from a Git repository.


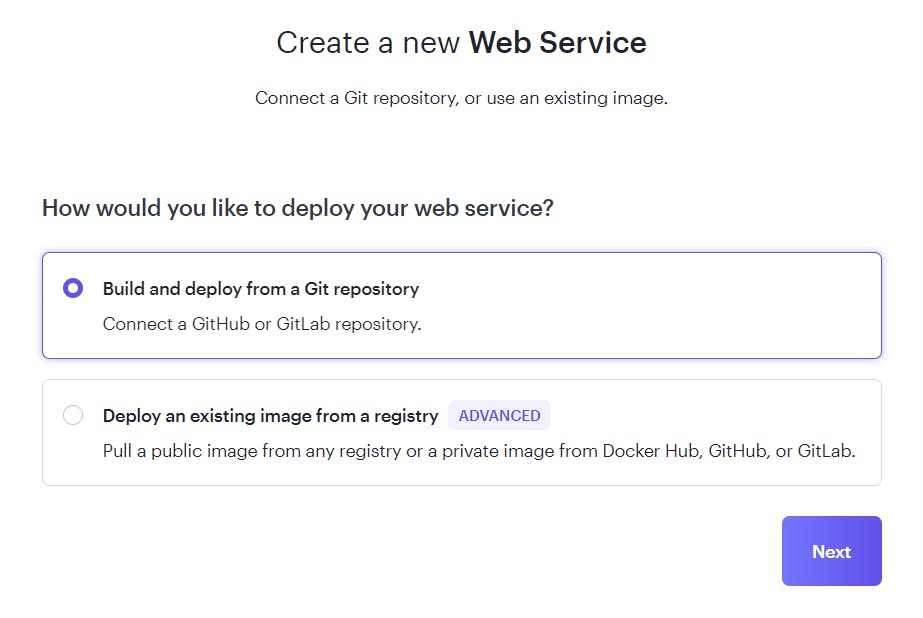
Connect with a GitHub, GitLab, or Bitbucket account. Your project must be in one of these repositories. In this example, we’re using GitHub as the source. If you aren’t sure how to upload a project, follow the GitHub documentation or your equivalent repository service instructions, which will explain it in detail. Once logged in, click Connect to the Node Unblocker project repository.


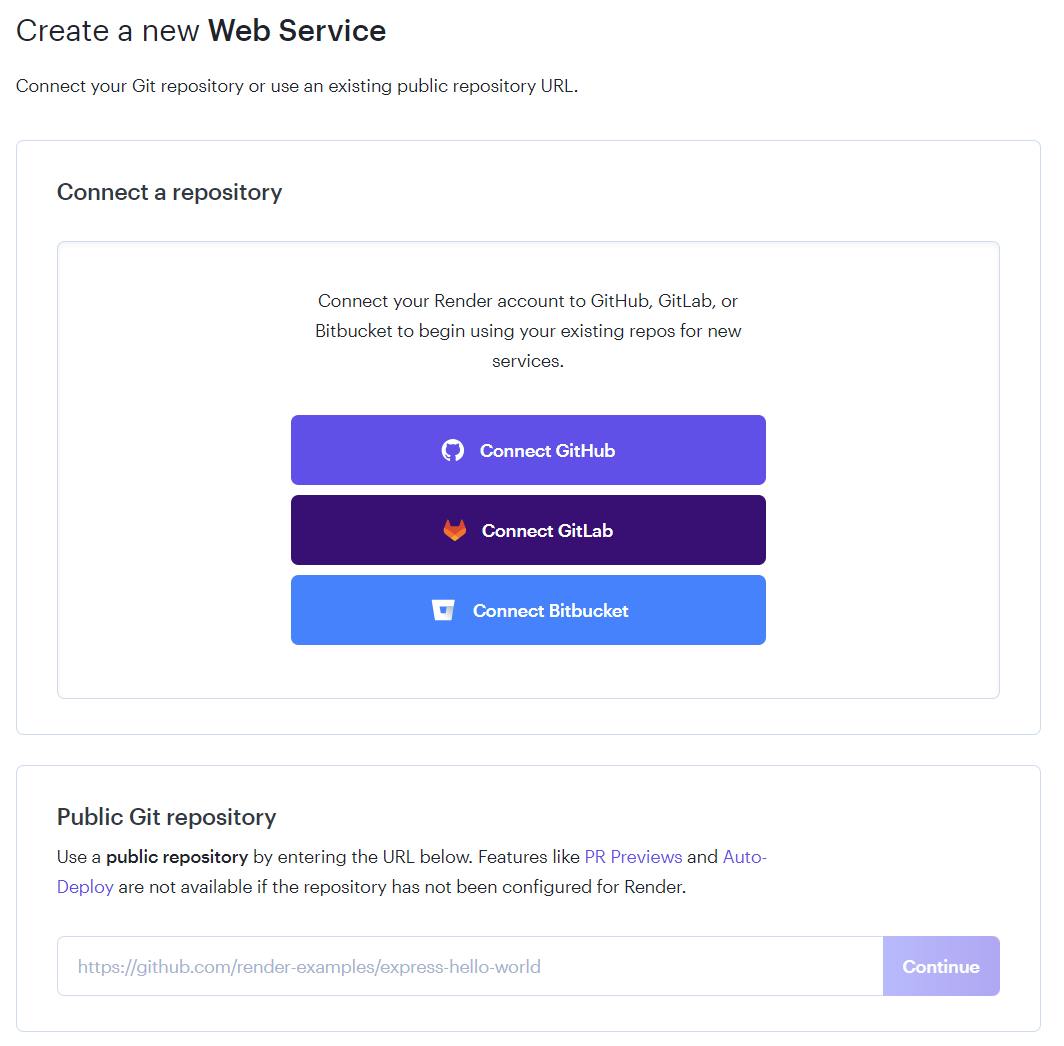


Set up various properties for your project or leave them at default. Then, click Create Web Service.


After a slight delay, your project will be deployed on the web! Copy the generated URL to test it out. Like how you used it in a local environment, you’ll need to attach the /proxy/ prefix and the URL you’re trying to access. In simple terms, the syntax would be:
[URL]/[prefix]/[target website]
For example, let’s access the Smartproxy website once again:
https://unblocker-94zv.onrender.com/proxy/https://smartproxy.com/
If the site loaded correctly, you’ve successfully deployed your project as a web service.
Scraping with Puppeteer
Now that the project exists on the web, we can use the URL with libraries that automate accessing the website, scraping the data you need, and returning it in a clean, readable format.
We’ll be using Puppeteer for this project. You’ll first need to install it by running the following command in your terminal tool:
npm i puppeteer
You can then write a simple script to access the website and scrape the needed data. For example, let’s scrape information from this example website, ScrapeMe. The goal is to get the name of the first item in the product list. Your script would look like this:
const puppeteer = require('puppeteer');(async () => {// Launch a headless browserconst browser = await puppeteer.launch();// Open a new pageconst page = await browser.newPage();// Navigate to the desired URLawait page.goto('https://unblocker-94zv.onrender.com/proxy/https://scrapeme.live/shop/');// Get the first item with class "woocommerce-loop-product__title"const firstItemTitle = await page.evaluate(() => {const firstItem = document.querySelector('.woocommerce-loop-product__title');return firstItem ? firstItem.textContent : null;});// Output the first item titleconsole.log(firstItemTitle);// Close the browserawait browser.close();})();
The script first launches a headless browser application and navigates to the target page. Since all store items share the same woocommerce-loop-product__title class, it identifies the first and prints the element's text content.
You can modify the code to extract different pieces of information or target different websites. If you’ve worked with Puppeteer or other scraping tools before, you’ll see that the process is entirely the same, only that the website will always be accessed through your deployed proxy web service.
Advantages of using Node Unblocker
Node Unblocker data collection use cases
Node Unblocker data collection serves various use cases, catering to diverse needs. Users often use it for unrestricted gaming experiences, seamless streaming access to geo-blocked content, and development testing by circumventing content restrictions. Read on to find out some of the most common usage purposes.
Web scraping for market research
Node Unblocker makes web scraping easier by bypassing restrictions on accessing websites. It allows you to collect data from various sources without being blocked, ensuring comprehensive data gathering for market analysis.
SEO and digital marketing analysis
By overcoming IP-based restrictions, Node Unblocker aids in gathering SEO and digital marketing data from various online platforms. Monitor search engine rankings, analyze social media trends, access competitor strategies, and get valuable insights for optimizing marketing campaigns.
Academic research
Node Unblocker can help you access and collect data from scholarly websites and databases. It ensures unrestricted access to academic papers, journals, and research material for your academic work.
Content aggregation
Node Unblocker enables content aggregation from multiple websites by circumventing geo-blocking and access restrictions. This allows you to compile diverse sources of information from news articles, posts, and media content to create comprehensive and up-to-date content repositories.
E-commerce and pricing strategy
Node Unblocker helps monitor competitor pricing, product availability, and customer reviews across many eCommerce platforms. It assists in devising competitive pricing strategies, optimizing product offerings, understanding market demand, and making informed decisions.
Real estate and property market analysis
With the help of Node Unblocker, you can access real estate listings, property data, and market trends from various online platforms and databases. You can then use this information to analyze property prices, market dynamics, and investment opportunities.
Travel and hospitality industry research
Collect data on travel destinations, hotel reviews, and tourism trends with the help of Node Unblocker. Analyze market demand, customer preferences, and competitive landscapes for strategic planning and marketing initiatives.
Supply chain and logistics monitoring
Node Unblocker facilitates access to supply chain and logistics data platforms. It allows you to track shipments more efficiently, monitor transportation routes, and analyze supply chain performance for enhanced visibility, efficiency, and risk management.
Conclusion
Node Unblocker offers an excellent solution for bypassing network restrictions with its impressive speed, reliability, and straightforward setup process. With Node Unblocker, users can enjoy swift and dependable access to restricted websites without complicated configuration, making it a standout option for those seeking a hassle-free browsing experience. For completely anonymous and safe web browsing, don’t forget to check out our proxy solutions. Your online activity will be hidden from both your service providers and the websites you’re visiting, ensuring complete privacy and security.
About the author
Martin Ganchev
VP Enterprise Partnerships
Martin, aka the driving force behind our business expansion, is extremely passionate about exploring fresh opportunities, fostering lasting relationships in the proxy market, and, of course, sharing his insights with you.
All information on Smartproxy Blog is provided on an "as is" basis and for informational purposes only. We make no representation and disclaim all liability with respect to your use of any information contained on Smartproxy Blog or any third-party websites that may be linked therein.